- Research Article
- Open access
- Published:
Opportunistic Adaptive Transmission for Network Coding Using Nonbinary LDPC Codes
EURASIP Journal on Wireless Communications and Networking volume 2010, Article number: 517921 (2010)
Abstract
Network coding allows to exploit spatial diversity naturally present in mobile wireless networks and can be seen as an example of cooperative communication at the link layer and above. Such promising technique needs to rely on a suitable physical layer in order to achieve its best performance. In this paper, we present an opportunistic packet scheduling method based on physical layer considerations. We extend channel adaptation proposed for the broadcast phase of asymmetric two-way bidirectional relaying to a generic number  of sinks and apply it to a network context. The method consists of adapting the information rate for each receiving node according to its channel status and independently of the other nodes. In this way, a higher network throughput can be achieved at the expense of a slightly higher complexity at the transmitter. This configuration allows to perform rate adaptation while fully preserving the benefits of channel and network coding. We carry out an information theoretical analysis of such approach and of that typically used in network coding. Numerical results based on nonbinary LDPC codes confirm the effectiveness of our approach with respect to previously proposed opportunistic scheduling techniques.
of sinks and apply it to a network context. The method consists of adapting the information rate for each receiving node according to its channel status and independently of the other nodes. In this way, a higher network throughput can be achieved at the expense of a slightly higher complexity at the transmitter. This configuration allows to perform rate adaptation while fully preserving the benefits of channel and network coding. We carry out an information theoretical analysis of such approach and of that typically used in network coding. Numerical results based on nonbinary LDPC codes confirm the effectiveness of our approach with respect to previously proposed opportunistic scheduling techniques.
1. Introduction
Intensive work has been devoted the field of network coding (NC) since the new class of problems called "network information flow" was introduced in the paper of Ahlswede et al. [1], in which the coding rate region of a single source multicast communication across a multihop network was determined and it was shown how message mixing at intermediate nodes (routers) allows to achieve such capacity. Linear network coding consists of linearly combining packets at intermediate nodes and, among other advantages [2], allows to increase the overall network throughput. In [3], NC is seen as an extension of the channel coding approach introduced by Shannon in [4] to the higher layers of the open systems interconnection (OSI) model of network architecture. Important theoretical results have been produced in the context of NC such as the min-cut max-flow theorem [5], through which an upper bound to network capacity can be determined, or the technique of random linear network coding [6, 7] that achieves the packet-level capacity for both single unicast and single multicast connections in both wired and wireless networks [3]. Practical implementations of systems where network coding is adopted have also been proposed, such as CodeCast in [8] and COPE in [9].
The implementation proposed in [9] is based on the idea of "opportunistic wireless network coding". In such scheme at each hop, the source chooses packets to be combined together so that each of the sinks knows all but one of the packets. Considering the problem in a wireless multihop scenario, each of the potential receivers will experiment different channel conditions due to fading and different path losses. At this point, a scheduling problem arises: which packets must be combined and transmitted? Several solutions to this scheduling problem have been proposed up to now. In [10], a solution based on information theoretical considerations is described, that consists of combining and transmitting, with a fixed rate, packets belonging only to nodes with highest channel capacities. The number of such nodes is chosen so as to maximize system throughput. In [11], the solution [10] has been adapted to a more practical scenario with given modulations and finite packet loss probabilities. In both cases network coding and channel coding are treated separately. However, as pointed out in the paper by Effros et al. [12], such approach is not optimal in real scenarios. In [13, 14], a joint network and channel coding approach has been adopted to improve transmissions in the two-way relay channel (TWRC) in which two nodes communicate with the help of a relay. One of the main ideas used in these works is that of applying network coding after channel encoding. This introduces a new degree of flexibility in channel adaptation, which leads to a decrease in the packet error rate of both receivers.
Up to our knowledge, this approach has been applied only to the two-way relay channel. In the present paper, we extend the basic idea of inverting channel and network coding to a network context. While in the TWRC the relay broadcasts combinations of messages received by the two nodes willing to communicate, in our setup the relay can have stored packets during previous transmissions by other nodes, which is typical in a multihop network, and transmit them to a set of  sinks. As a matter of fact, in a wireless multihop network more than just two nodes (sinks) are likely to overhear a given transmission. Due to the different channel conditions, a per-sink channel adaptation is done in order to enhance link reliability and decrease frequent retransmissions which can congest parts of the network, especially when ARQ mechanisms are used [9]. In particular, packet
sinks. As a matter of fact, in a wireless multihop network more than just two nodes (sinks) are likely to overhear a given transmission. Due to the different channel conditions, a per-sink channel adaptation is done in order to enhance link reliability and decrease frequent retransmissions which can congest parts of the network, especially when ARQ mechanisms are used [9]. In particular, packet  of length
of length  is considered as a buffer by the transmitting node (source node). At each transmission, a part of the buffer, containing
is considered as a buffer by the transmitting node (source node). At each transmission, a part of the buffer, containing  bits, is included in a new packet of total length
bits, is included in a new packet of total length  that contains
that contains  bits of redundancy. Network Coding combination takes place on such packets. The value of
bits of redundancy. Network Coding combination takes place on such packets. The value of  , which determines the amount of redundancy to be introduced in each combined packet (i.e., the code rate), is chosen by the source node considering the physical channel between source node and sink
, which determines the amount of redundancy to be introduced in each combined packet (i.e., the code rate), is chosen by the source node considering the physical channel between source node and sink  . Given a set of channel code rates
. Given a set of channel code rates  , we propose that the code rate in channel
, we propose that the code rate in channel  be the one that maximizes the effective throughput on link
be the one that maximizes the effective throughput on link  defined as
defined as

where  is the current probability of packet loss on channel
is the current probability of packet loss on channel  when using rate
when using rate  .
.
In present paper, we carry out an information theoretical analysis and comparison for the proposed method and the method in [10], which maximizes overall throughput in a system where opportunistic network coding is used, showing how the first one noticeably enhances system throughput. Moreover, we evaluate the performance of the two methods in a real system using capacity-approaching nonbinary low-density parity-check (LDPC) codes at various rates (in [13, 14] parallel concatenated convolutional codes (PCCC) have been adopted for channel coding). Numerical results confirm those obtained analytically. Finally, we consider some issues regarding how modifications at physical level affect network coding from a network perspective.
The paper is organized as follows. In Section 2, the system model is described. In Section 3, we propose a benchmark system with equal rate link adaptation. Section 4 contains the description of our proposed opportunistic adaptive transmission for network coding. In Section 5, we carry out the comparison between the two methods by comparing the cumulative density functions of the throughput and the ergodic achievable rates. Section 6 contains the description of the simulation setup and the numerical results. In Section 7, we consider some scheduling and implementation issues at network level that arise from applying the proposed adaptive transmission method, and finally in Section 8, we draw the conclusions about the results obtained in this paper, and we suggest possible future work to be carried out.
2. System Model
2.1. Network Level
Let us consider a mobile wireless multihop network such as the one depicted in Figure 1. We denote by  the finite field (Galois field) of order
the finite field (Galois field) of order  . Each packet is an element in
. Each packet is an element in  ; that is, it is a
; that is, it is a  -dimensional vector with components in
-dimensional vector with components in  . We say that a node
. We say that a node  is the generator of a packet
is the generator of a packet  if the packet
if the packet  originated in
originated in  . We say that a node is the source node during a transmission slot if it is the node which is transmitting. We call sink node the receiving node during a given transmission slot and destination node the node to which a given packet is addressed. We will refer to generators' packets as native packets. Each node stores overheard packets. Native and overheard packets are transmitted to neighbor nodes. For ease of exposition and without loss of generality we assume that a collision-free time division multiple access is in place. The number of hops needed to transmit a packet from generator to destination node depends on the relative position of the two nodes in the network. In Figure 1, two generator-destination pairs are shown (
. We say that a node is the source node during a transmission slot if it is the node which is transmitting. We call sink node the receiving node during a given transmission slot and destination node the node to which a given packet is addressed. We will refer to generators' packets as native packets. Each node stores overheard packets. Native and overheard packets are transmitted to neighbor nodes. For ease of exposition and without loss of generality we assume that a collision-free time division multiple access is in place. The number of hops needed to transmit a packet from generator to destination node depends on the relative position of the two nodes in the network. In Figure 1, two generator-destination pairs are shown ( ,
,  ). Thin dashed lines in the figure represent wireless connectivity between nodes and thick lines represent packet transmissions.
). Thin dashed lines in the figure represent wireless connectivity between nodes and thick lines represent packet transmissions.  has a packet to deliver to
has a packet to deliver to  and
and  has a packet to deliver to node
has a packet to deliver to node  . In the first time slot, generator
. In the first time slot, generator  and
and  broadcast their packets
broadcast their packets  and
and  , respectively, (thick red dash-dotted line). In the second time slot, node 6 acts as a source node broadcasting packet
, respectively, (thick red dash-dotted line). In the second time slot, node 6 acts as a source node broadcasting packet  (thick green dotted line) received in previous slot. Note that in this case node 6 is a source node but not a generator node. Finally, in the third time slot, node 5 broadcasts the linear combination in a finite field of packets
(thick green dotted line) received in previous slot. Note that in this case node 6 is a source node but not a generator node. Finally, in the third time slot, node 5 broadcasts the linear combination in a finite field of packets  and
and  (indicated in Figure 1 with
(indicated in Figure 1 with  +
+  ). Destination nodes
). Destination nodes  and
and  can, respectively, obtain packets
can, respectively, obtain packets  and
and  from
from  +
+  using their knowledge about packets
using their knowledge about packets  and
and  overheard during previous transmissions.
overheard during previous transmissions.

Mobile wireless multihop network. Two different information flows exist between two generator-destination pairs  and
and  . Thin dashed lines represent wireless connectivity among nodes while thick lines represent packet transmissions. In the first time slot generator
. Thin dashed lines represent wireless connectivity among nodes while thick lines represent packet transmissions. In the first time slot generator  1 and
1 and  2 broadcast their packets
2 broadcast their packets  and
and  , respectively, (thick dash-dotted line). In the second time slot, node 6 broadcasts packet
, respectively, (thick dash-dotted line). In the second time slot, node 6 broadcasts packet  (thick dotted line) received in previous slot. In the third time slot, node 5 broadcasts the linear combination of packets
(thick dotted line) received in previous slot. In the third time slot, node 5 broadcasts the linear combination of packets  and
and  (
( ). Destination nodes
). Destination nodes  and
and  can, respectively, obtain packets
can, respectively, obtain packets  and
and  from
from  using their knowledge about packets
using their knowledge about packets  and
and  overheard during previous transmissions.
overheard during previous transmissions.
In general, using linear network coding we proceed as follows. Each node stores overheard packets, linearly combines them and transmits the combination together with the combination coefficients. As the combination is linear and coefficients are known, a node can decode all packets if and only if it receives a sufficient number of linearly independent combinations of the same packets. At this point, a scheduling solution must be found in order to decide which packets must be combined and transmitted each time. In the paper by Katti et al. [9], a packet scheduling based on the concept of network group has been described. Such solution, called opportunistic coding, consists of choosing packets so that each neighbor node knows all but one of the encoded packets. Such approach has been implemented in the COPE protocol, and its practical feasibility has been shown in [9]. A network group is formally defined as follows.
Definition 1.
A set of nodes is called a size  network group (NG) if it satisfies the following:
network group (NG) if it satisfies the following:
-
(1)
one of the nodes (source) has a set
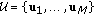 of
of  native packets to be delivered to the other nodes in the set (sinks);
native packets to be delivered to the other nodes in the set (sinks); -
(2)
all sink nodes are within the transmission range of the source;
-
(3)
each of the sink nodes has all packets in
 but one (they may have received them during previous transmissions).
but one (they may have received them during previous transmissions).
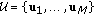 of
of  native packets to be delivered to the other nodes in the set (sinks);
native packets to be delivered to the other nodes in the set (sinks); but one (they may have received them during previous transmissions).
but one (they may have received them during previous transmissions).All native packets are assumed to contain the same number K of symbols. A native packet is considered as a  -dimensional vector with components in
-dimensional vector with components in  with
with  , that is, a native packet is an element in
, that is, a native packet is an element in  .
.
Figure 2 shows an example of how a network group is formed during a transmission slot.

Network group formation. 4 is going to access the channel. Node
4 is going to access the channel. Node  4 knows which packets are stored in its neighbors' buffers. Based on this knowledge it must choose which packets to XOR together in order to maximize the number of packets decoded in the transmission slot. A possible choice is, for example,
4 knows which packets are stored in its neighbors' buffers. Based on this knowledge it must choose which packets to XOR together in order to maximize the number of packets decoded in the transmission slot. A possible choice is, for example,  which allows nodes
which allows nodes  1 and
1 and  2 to decode, but not
2 to decode, but not  . A better choice is to encode
. A better choice is to encode 



 , so that 3 packets can be decoded in a single transmission. The difference in SNR for the three sinks (
, so that 3 packets can be decoded in a single transmission. The difference in SNR for the three sinks ( ,
, , and
, and  ) can lead to high packet loss probability on some of the links if a single channel rate is used for all the sinks.
) can lead to high packet loss probability on some of the links if a single channel rate is used for all the sinks.  is the vector of SNRs.
is the vector of SNRs.
Network groups appear in practical situations in wireless mesh networks and other systems. A classical example is a bidirectional link where two nodes communicate through a relay. More examples can be found in [9]. In the following, we will assume that all transmissions adopt the network group approach; that is, during each transmission slot, the source node chooses the packets to be combined so that each of the sinks knows all but one of the packets. As a matter of fact, if nodes are close one to each other it is highly probable that many of them overhear the same packets. Nevertheless this assumption is not necessary to obtain NC gain or to apply the technique proposed in this paper. In Section 7, we will extend the results to a more general case, in which a node may not know more than one of the source packets.
We assume time is divided into transmission slots. During each transmission slot source node combines together the  packets in
packets in  and broadcasts the resulting packet to sink nodes of the network group. Let us indicate with
and broadcasts the resulting packet to sink nodes of the network group. Let us indicate with  the packet to be delivered to node
the packet to be delivered to node  . The packet transmitted by the source node is
. The packet transmitted by the source node is

where  indicates the sum in
indicates the sum in  . Let us define packet
. Let us define packet  as follows:
as follows:

Sink  can obtain
can obtain  by adding
by adding  and
and  in
in  , where
, where  is known according to our assumptions.
is known according to our assumptions.
Note that in the network in Figure 1 many aspects deserve in-depth study, such as end-to-end scheduling of packet transmissions on multiple access schemes. These aspects are however beyond the scope of this paper, where we focus on maximizing the efficiency of transmissions within a network group.
2.2. Physical Level
Physical links between source and sinks are modeled as frequency-flat, slowly time-variant (block fading) channels. The SNR of sink i during time slot t can be expressed as

where  is the power used by source node during transmission,
is the power used by source node during transmission,  is a Rayleigh distributed random variable that models the fading,
is a Rayleigh distributed random variable that models the fading,  is the distance between source and sink
is the distance between source and sink  ,
,  is the path loss exponent and
is the path loss exponent and  is the variance of the AWGN at sink nodes. From expression (4) it can be seen that the SNR at a receiver with a given
is the variance of the AWGN at sink nodes. From expression (4) it can be seen that the SNR at a receiver with a given  is an exponentially distributed random variable with probability density function
is an exponentially distributed random variable with probability density function

where  is the mean value of the SNR. We assume that the quantities
is the mean value of the SNR. We assume that the quantities  at the various sinks are i.i.d. random variables. In the model we are not taking into account shadowing effects.
at the various sinks are i.i.d. random variables. In the model we are not taking into account shadowing effects.
3. Constant Information Rate Opportunistic Scheduling Solutions
Based on the propagation model in (5), the channel from source to each sink will have a different gain. The difference in link states experienced by the sinks gives rise to the problem of how to choose the broadcast transmission rate. In [10], an interesting solution has been proposed based on information-theoretical capacity considerations. Sink nodes are ordered from 1 to  with increasing SNR. The solution proposed consists of combining and transmitting only packets having as destination the
with increasing SNR. The solution proposed consists of combining and transmitting only packets having as destination the  sinks with highest SNR. The transmission rate
sinks with highest SNR. The transmission rate  chosen by the source node is the lowest capacity in the group of
chosen by the source node is the lowest capacity in the group of  channels. The instantaneous capacity obtained during each transmission is then
channels. The instantaneous capacity obtained during each transmission is then

where  is the SNR experienced on the
is the SNR experienced on the  th worse channel.
th worse channel.  is chosen so that (6) is maximized. Note that all sinks in the network group receive the same amount of information per packet. In [11], another approach is proposed in which the source node transmits to all nodes in the NG. A practical transmission scheme with finite bit error probability and fixed modulations is described.
is chosen so that (6) is maximized. Note that all sinks in the network group receive the same amount of information per packet. In [11], another approach is proposed in which the source node transmits to all nodes in the NG. A practical transmission scheme with finite bit error probability and fixed modulations is described.
3.1. Constant Information Rate Benchmark
Based on [10, 11], we define a constant information rate (CIR) system that will be used as a benchmark to our proposed adaptive system. Let us now define the effective throughput as

where  and
and  are two
are two  vectors containing, respectively, the packet loss probabilities and the coding rates for the various links,
vectors containing, respectively, the packet loss probabilities and the coding rates for the various links,  represents the transpose operator and
represents the transpose operator and  is an
is an  -dimensional vector of all ones. The quantity expressed in (7) measures the average information flow (bits/sec/Hz) from source to sinks.
-dimensional vector of all ones. The quantity expressed in (7) measures the average information flow (bits/sec/Hz) from source to sinks.  is an
is an  -dimensional function that depends on the modulation scheme, coding rate vector
-dimensional function that depends on the modulation scheme, coding rate vector  and SNR vector
and SNR vector  . We assume channel state information (CSI) at both transmitter and receiver (i.e., the source knows vector
. We assume channel state information (CSI) at both transmitter and receiver (i.e., the source knows vector  containing the SNR of all sinks and node
containing the SNR of all sinks and node  knows
knows  ).
).
In the CIR system, the source calculates first the rate of the channel encoder which maximizes the effective throughput for each sink (individual effective throughput). Formally, for each sink  , we calculate
, we calculate

where  is the packet loss probability on the
is the packet loss probability on the  th link depending on the rate
th link depending on the rate  . For each rate
. For each rate  , we define
, we define  as the number of sinks for which
as the number of sinks for which

At this point, for each  we calculate the effective throughput, setting
we calculate the effective throughput, setting  where
where  is a
is a  -dimensional vector of all ones. Finally, we choose
-dimensional vector of all ones. Finally, we choose  to maximize the effective throughput. Note that with the CIR approach only sinks whose optimal rate is greater or equal than the rate which maximizes the total effective throughput will receive data.
to maximize the effective throughput. Note that with the CIR approach only sinks whose optimal rate is greater or equal than the rate which maximizes the total effective throughput will receive data.
4. Opportunistic Adaptive Transmission for Network Coding
We propose a scheme in which information rate is adapted to each sink's channel. This can be accomplished by inverting the order of channel coding and network coding at the source. In order to explain our method, let us consider again Figure 2. In the figure, a network group is depicted, in which node 4 accesses the channel as source node ( ) and nodes
) and nodes  1,
1,  2 and
2 and  3 are the sink nodes.
3 are the sink nodes.
As mentioned in Section 2, the source is assumed to know the packets in each sink (this can be accomplished with a suitable ACK mechanism such as the one described in [9]). We propose a transmission scheme for a size  Network Group consisting in
Network Group consisting in  variable-rate channel encoders, a
variable-rate channel encoders, a  adder and a modulator as shown in Figure 3. We assume CSI at both ends. The transmission scheme is as follows. Based on the SNR to sink
adder and a modulator as shown in Figure 3. We assume CSI at both ends. The transmission scheme is as follows. Based on the SNR to sink  ,
,  , the source chooses the code rate
, the source chooses the code rate  that maximizes the throughput to sink
that maximizes the throughput to sink  ,
,  . Overall, the rate vector chosen by the source is the one that maximizes the effective throughput, defined as
. Overall, the rate vector chosen by the source is the one that maximizes the effective throughput, defined as

As we are under the hypothesis of independent channel gains, optimal rate can be found independently for each physical link. In order to apply our method to a packet network, we fix the size of coded packets to  symbols. Channel adaptation is performed by varying the number of information symbols in the coded packet. So, referring to Figure 3, once the optimal rate
symbols. Channel adaptation is performed by varying the number of information symbols in the coded packet. So, referring to Figure 3, once the optimal rate  has been chosen for link
has been chosen for link  ,
,  , the source takes
, the source takes  information symbols from native packet
information symbols from native packet  and encodes them with a rate
and encodes them with a rate  encoder, thus obtaining a packet
encoder, thus obtaining a packet  of exactly
of exactly  symbols. Finally, packets
symbols. Finally, packets  are added in
are added in  , modulated and transmitted. On the receiver side, sink
, modulated and transmitted. On the receiver side, sink  is assumed to know a priori the rate used by the source for packet
is assumed to know a priori the rate used by the source for packet  as it can be estimated using CSI.
as it can be estimated using CSI.

Transmission scheme at source node for the proposed adaptive transmission scheme: the number of information symbols per packet addressed to a given sink is adapted to the sink's channel status using channel encoders at different rates. In the picture, the packet length at the output of the various blocks is indicated.
As previously stated we will assume that a constant energy per channel symbol is used. We will not consider the case of constant energy per information bit as packet combination at source node is done in  before channel symbol amplification.
before channel symbol amplification.
As we will see in Section 6, in this paper, we consider nonbinary LDPC codes which have a word error rate characteristic (WER) versus SNR with a high slope. Thus, the packet loss probability is negligible ( 10−3) beyond a given SNR threshold and rapidly rises below the threshold. The threshold depends of the code rate considered. Under this assumption, (10) can be approximated with
10−3) beyond a given SNR threshold and rapidly rises below the threshold. The threshold depends of the code rate considered. Under this assumption, (10) can be approximated with

where  takes value 1 if
takes value 1 if  and 0 otherwise,
and 0 otherwise,  being a threshold that depends on the rate
being a threshold that depends on the rate  . We will refer to our approach as adaptive information rate (AIR), indicating that the number of information bits per packet received by a given sink is adapted to its channel status. The same approximation regarding
. We will refer to our approach as adaptive information rate (AIR), indicating that the number of information bits per packet received by a given sink is adapted to its channel status. The same approximation regarding  will be used for the CIR system.
will be used for the CIR system.
5. Information Theoretical Analysis
Let us consider a system where opportunistic network coding [9] is used. As described in Section 2, opportunistic Network Coding consists in a source node combining together and transmitting  native packets to
native packets to  sinks. Each of the sinks knows a priori all but one of the native packets (see Figure 2). Each of the receivers can, then, remove such known packets in order to obtain the unknown one. In the following, we provide an outline of the achievability for the achievable rate of the system, based on the results in [15] for the broadcast channel with side information [16]. In order to study the proposed adaptive transmission method we need to introduce an equivalent theoretical model. We model each of the
sinks. Each of the sinks knows a priori all but one of the native packets (see Figure 2). Each of the receivers can, then, remove such known packets in order to obtain the unknown one. In the following, we provide an outline of the achievability for the achievable rate of the system, based on the results in [15] for the broadcast channel with side information [16]. In order to study the proposed adaptive transmission method we need to introduce an equivalent theoretical model. We model each of the  packets stored in the source node as an information source. Thus an equivalent model for our system is given by a scheme with a set of
packets stored in the source node as an information source. Thus an equivalent model for our system is given by a scheme with a set of  information sources
information sources  all located in the source node, and a set of
all located in the source node, and a set of  sinks
sinks  . Information source
. Information source  produces a message addressed to sink
produces a message addressed to sink  who has side information (perfect knowledge, specifically) about messages produced by sources in the subset
who has side information (perfect knowledge, specifically) about messages produced by sources in the subset  . This models the situation in which each of the sinks knows all but one of the messages transmitted by source node (see Figure 2). Figure 4 depicts the equivalent model. Let us consider the system we described in Section 4. The theoretical idea behind such system is to adapt the information rate of each information source
. This models the situation in which each of the sinks knows all but one of the messages transmitted by source node (see Figure 2). Figure 4 depicts the equivalent model. Let us consider the system we described in Section 4. The theoretical idea behind such system is to adapt the information rate of each information source  to channel
to channel  . Each information source
. Each information source  chooses a message from a set of
chooses a message from a set of  different messages. An
different messages. An  -dimensional channel code book is randomly created according to a distribution
-dimensional channel code book is randomly created according to a distribution  and revealed to both sender and receiver. The number of sequences in the channel code book is
and revealed to both sender and receiver. The number of sequences in the channel code book is  . Source node produces a set of
. Source node produces a set of  messages, one for each information source in it. Given a set of messages, the corresponding channel codeword
messages, one for each information source in it. Given a set of messages, the corresponding channel codeword  is selected and transmitted over the channel. Sink
is selected and transmitted over the channel. Sink  decodes the output
decodes the output  of his channel by fixing
of his channel by fixing  dimensions in the channel code book using its side information about the set of information sources
dimensions in the channel code book using its side information about the set of information sources  and applying typical set decoding along dimension
and applying typical set decoding along dimension  . If we impose that for each information source
. If we impose that for each information source  where
where  and
and  are, respectively, the input and output of a channel where only transmission to sink
are, respectively, the input and output of a channel where only transmission to sink  takes place, then an achievable rate for the system is the sum of the instantaneous achievable rates of the various links
takes place, then an achievable rate for the system is the sum of the instantaneous achievable rates of the various links


Equivalent scheme for adaptive transmission. information sources
information sources  are located in the source node. Information source
are located in the source node. Information source  produces a message addressed to sink
produces a message addressed to sink  which has previous knowledge of messages produced by information sources in the subset
which has previous knowledge of messages produced by information sources in the subset  .
.  represents the probability transition function of the channel between the source node and sink
represents the probability transition function of the channel between the source node and sink  .
.
Let us now consider the scheduling solution proposed in [10]. According to this solution, sinks are ordered from  to
to  with increasing channel quality. The
with increasing channel quality. The  information sources aiming to transmit to the
information sources aiming to transmit to the  sinks with best channels (i.e., sinks
sinks with best channels (i.e., sinks  ) are selected. Each information source in the source node chooses a message from a set of
) are selected. Each information source in the source node chooses a message from a set of  elements, where
elements, where  is chosen so that
is chosen so that  . This means that only sinks whose channels have instantaneous capacity greater than or equal to node
. This means that only sinks whose channels have instantaneous capacity greater than or equal to node  can decode their message. Only information sources that produce messages addressed to these nodes are selected for transmission. An achievable rate for this system can be obtained from (12) by setting to
can decode their message. Only information sources that produce messages addressed to these nodes are selected for transmission. An achievable rate for this system can be obtained from (12) by setting to  the first
the first  terms in the sum, setting the others equal to
terms in the sum, setting the others equal to  and optimizing with respect to
and optimizing with respect to 

where  indicates the
indicates the  th worst channel SNR. In order to compare the two approaches, we will consider the probability, or equivalently the percentage of time, during which each of the systems achieves a rate lower than a given value
th worst channel SNR. In order to compare the two approaches, we will consider the probability, or equivalently the percentage of time, during which each of the systems achieves a rate lower than a given value  , that is,
, that is,

where  is the cumulative density function of the variable
is the cumulative density function of the variable  . In the constant information rate system such probability is
. In the constant information rate system such probability is

We calculated thisexpression for a network with a generic number  of nodes (see Appendix A). Such expression is given by
of nodes (see Appendix A). Such expression is given by

where

for  , and
, and

 being the mean value of the SNR, assumed to be exponentially distributed.
being the mean value of the SNR, assumed to be exponentially distributed.
Let us now consider the cumulative density function for our proposed system (adaptive information rate). By definition we have

where:

 being a function that assumes value 0 for
being a function that assumes value 0 for  and 1 for
and 1 for  . Expression (19) is difficult to calculate in closed form for the general case. For the low SNR regime we calculated the following expression (see Appendix B):
. Expression (19) is difficult to calculate in closed form for the general case. For the low SNR regime we calculated the following expression (see Appendix B):

In Figure 5, expressions (16) and (21) are compared for a Network Group of 5 nodes and an average SNR of −10 dB. The Montecarlo simulation of our system is also plotted for comparison with (21). At higher SNR (see Figure 6), the CDF of AIR system is upper bounded by (16) and loosely lower bounded by the (21) (see Appendix B). A better lower bound is given by (see Appendix B):


Comparison between cumulative density functions in the system with constant information rate (CIR), adaptive information rate (AIR) and Montecarlo simulation of AIR. For each value of  , the constant rate system has a probability not to achieve a rate equal or greater that
, the constant rate system has a probability not to achieve a rate equal or greater that  which is higher with respect to our system. Equivalently, our system will be transmitting at a rate higher than
which is higher with respect to our system. Equivalently, our system will be transmitting at a rate higher than  for a greater percentage of time.
for a greater percentage of time.

Comparison between cumulative density functions of the two systems with  nodes and SNR = 5 dB. We can see how for the 40% of time the rate of AIR system will be above 8 bits/s/Hz while CIR system achievable rate will be above 5.2 bits/s/Hz. At high SNR the (21) is a loose upper bound for the (19). A tighter lower bound is given by 22 which is also plotted.
nodes and SNR = 5 dB. We can see how for the 40% of time the rate of AIR system will be above 8 bits/s/Hz while CIR system achievable rate will be above 5.2 bits/s/Hz. At high SNR the (21) is a loose upper bound for the (19). A tighter lower bound is given by 22 which is also plotted.
The ergodic achievable rate of the two systems can now be calculated. For the constant information rate system, we have

where  is given by (16).
is given by (16).
As for the system with adaptive information rate, we have

where  is the exponential integral defined as
is the exponential integral defined as

In Figure 7, the average achievable rate of the two systems, assuming constant transmitted power, is plotted against the mean SNR for AIR and CIR systems with  nodes.
nodes.

Ergodic achievable rate for AIR and CIR systems for a Network Coding group with  = 5 nodes. The high values of the rates are due to NC gain. We see how AIR system gains about 2 bits/sec/Hz in all the considered SNR range.
= 5 nodes. The high values of the rates are due to NC gain. We see how AIR system gains about 2 bits/sec/Hz in all the considered SNR range.
6. Simulation Setup and Results
In this section, we describe the implementation of the proposed scheme using nonbinary LDPC codes and soft decoding.
6.1. Notation
During each transmission slot the source node combines together the packets in  (see Section 4) and broadcasts the resulting packet to sink nodes of the network group. In this paper, we used the DaVinci codes, that is, the nonbinary LDPC codes from the DaVinci project [17]. For such codes the order of the Galois field is
(see Section 4) and broadcasts the resulting packet to sink nodes of the network group. In this paper, we used the DaVinci codes, that is, the nonbinary LDPC codes from the DaVinci project [17]. For such codes the order of the Galois field is  , that is, each GF symbol corresponds to
, that is, each GF symbol corresponds to  bits. We denote the elements of the finite field by
bits. We denote the elements of the finite field by  , where
, where  is the additive identity.
is the additive identity.
 denotes the message of user
denotes the message of user  , of length
, of length  symbols, that is,
symbols, that is,  bits.
bits.  is the codeword of user
is the codeword of user  , of length
, of length  symbols, that is,
symbols, that is,  bits, constant for all users.
bits, constant for all users.
6.2. L-Vectors
A codeword  contains
contains  code symbols. At the receiver, the demapper provides the decoder with an LLR-vector (log-likelihood ratio) of dimension
code symbols. At the receiver, the demapper provides the decoder with an LLR-vector (log-likelihood ratio) of dimension  for each code symbol, that is, for each codeword, the demapper has to compute
for each code symbol, that is, for each codeword, the demapper has to compute  real values.
real values.
The LLR-vector corresponding to code symbol  is defined as
is defined as  , with
, with

For  -QAM and a channel code defined over
-QAM and a channel code defined over  , this simplifies to (see e.g., [18])
, this simplifies to (see e.g., [18])

where  is the mapping function, which maps a code symbol to a QAM constellation point, the noise is
is the mapping function, which maps a code symbol to a QAM constellation point, the noise is  distributed and
distributed and  is the channel coefficient.
is the channel coefficient.
6.3. Network Decoding for LLR-Vectors
We want to compute the LLR-vector of user  , having received
, having received  .
.  is the sum (defined in
is the sum (defined in  ) of all codewords.
) of all codewords.
We assume that user  knows the sum of all other codewords
knows the sum of all other codewords

Then the LLR-vector of user  for code symbol
for code symbol  is
is

The sum in the indices is defined in  . In Figure 8 the block scheme of the
. In Figure 8 the block scheme of the  th receiver is illustrated.
th receiver is illustrated.

Receiver scheme for node  . The demapper provides the decoder with L vectors relative to received symbols. Network decoder uses knowledge of symbol
. The demapper provides the decoder with L vectors relative to received symbols. Network decoder uses knowledge of symbol  to calculate
to calculate  vector, that is, the
vector, that is, the  vector of
vector of  .
.

Word error rate (WER) for nonbinary LDPC codes at various rates. The high slopes of the curves allow to define thresholds for the various rates, such that a very low word error rate ( 10−3) is achieved beyond the threshold, while it rapidly increases before such thresholds.
10−3) is achieved beyond the threshold, while it rapidly increases before such thresholds.
Note that in our scheme, we have inverted the order of network and channel coding, while doing soft decoding at the receiver. This approach has the important advantage of allowing rate adaptation while fully preserving the advantages of channel and network coding.
The network coding stage is transparent to the channel coding scheme; that is, the channel seen by the channel decoder is equivalent to the channel without network coding. This is the reason why no specific design of the channel code is required for the proposed scheme.
6.4. Rate Adaptation
For  -QAM with the DaVinci codes of length
-QAM with the DaVinci codes of length  code symbols and rates
code symbols and rates  , we obtain the following word error rate (WER) curves.
, we obtain the following word error rate (WER) curves.
For a target WER of  , this leads to the SNR thresholds of Table 1.
, this leads to the SNR thresholds of Table 1.
 and the coding rate
and the coding rate  are indicated for each SNR threshold. Note that for each threshold we have:
are indicated for each SNR threshold. Note that for each threshold we have:  , that is, all encoded packets have the same length.
, that is, all encoded packets have the same length.6.5. Simulation Results
In the following, the channel is block Rayleigh fading with average SNR  . For
. For  users, sum rates for the proposed system and for the benchmark system are depicted in Figure 10.
users, sum rates for the proposed system and for the benchmark system are depicted in Figure 10.

Sum rate for AIR and CIR systems for a Network Coding group with  = 5 nodes. Variable rate nonbinary LDPC codes with 64 QAM modulation have been used. The high values of the rates are due to NC gain. We see how AIR system gains about 2 bits/channel use in the higher SNR range. It is interesting to note that almost the same gain has been calculated in Section 5 when considering the average achievable rates for CIR and AIR systems with the same number of nodes at lower SNRs.
= 5 nodes. Variable rate nonbinary LDPC codes with 64 QAM modulation have been used. The high values of the rates are due to NC gain. We see how AIR system gains about 2 bits/channel use in the higher SNR range. It is interesting to note that almost the same gain has been calculated in Section 5 when considering the average achievable rates for CIR and AIR systems with the same number of nodes at lower SNRs.
Next, we consider two users, where the first one has average SNR  and the second one
and the second one  , that is,
, that is,  dB less. The resulting rates are depicted in Figure 11.
dB less. The resulting rates are depicted in Figure 11.

Comparison of the rates of two nodes belonging to a Network Coding group with  = 2 nodes in both AIR and CIR systems. One of the nodes suffers from a higher path loss attenuation (10 dB) with respect to the other. Node with better channel in AIR system achieves higher rate with respect to node with better channel in CIR system. The gain arises from adapting the coding rate of each node to the channel independently from the other nodes.
= 2 nodes in both AIR and CIR systems. One of the nodes suffers from a higher path loss attenuation (10 dB) with respect to the other. Node with better channel in AIR system achieves higher rate with respect to node with better channel in CIR system. The gain arises from adapting the coding rate of each node to the channel independently from the other nodes.
As before, the error rate is very low in both cases (the adaptation is designed such that  , and this is fulfilled.)
, and this is fulfilled.)
7. Implementation
In this section, we discuss some issues arising by the application of our proposed scheme. In particular we discuss a generalization of network groups, in order to apply our method to a real system, the effects of packet fragmentation due to the use of different code rates and the implications our method has on system fairness.
7.1. Generalized Network Group
In Section 2, we assumed that, at each transmission, the source combines so that each of the sinks knows all but one of the packets. This assumption can be relaxed, leading to a more general case which makes our scheme usable in most situations arising in practice. Let us consider a generalized network group of size  . The source has a set of packets
. The source has a set of packets  while sink
while sink  has a set of packets
has a set of packets  lacking one or more packets in
lacking one or more packets in  . Let us now define the set
. Let us now define the set  as
as

where  denotes the complement of
denotes the complement of  . In other words,
. In other words,  represents all packets which are common to all sinks but sink
represents all packets which are common to all sinks but sink  . The source transmits to node
. The source transmits to node  one of the packets in the set
one of the packets in the set  (i.e., all packets in
(i.e., all packets in  which are known to the source node). Thus, if we indicate with
which are known to the source node). Thus, if we indicate with  the cardinality of set
the cardinality of set  , the sink
, the sink  will need
will need  linearly independent (in
linearly independent (in  ) packets in order to decode all the
) packets in order to decode all the  original native packets [19]. Such l.i. packets can be obtained from the same source node or from other nodes in the network which previously stored the packets. With such scheme a total of
original native packets [19]. Such l.i. packets can be obtained from the same source node or from other nodes in the network which previously stored the packets. With such scheme a total of  transmission phases are needed for all the sinks to know all the packets. As a special case, if
transmission phases are needed for all the sinks to know all the packets. As a special case, if  for all
for all  , we have the NG considered in Section 2.
, we have the NG considered in Section 2.
In order to understand how to proceed when more than one packet is unknown at one or more sinks, define an  -dimensional vector space associated to the source packet set
-dimensional vector space associated to the source packet set  . A canonical basis for this space is defined as
. A canonical basis for this space is defined as  . The transmitted packet is a linear combination of this basis,
. The transmitted packet is a linear combination of this basis,  .
.
The sets of missing packets in sink  ,
,  , define a
, define a  -dimensional space. In the concept of network group described in Section 2, the transmitted packet is obtained as
-dimensional space. In the concept of network group described in Section 2, the transmitted packet is obtained as  , which is linearly independent from the subspace spanned by the packets owned by sinks
, which is linearly independent from the subspace spanned by the packets owned by sinks  . As a result, the packets contained in each sink together with
. As a result, the packets contained in each sink together with  span the whole space
span the whole space  , therefore all packets can be decoded.
, therefore all packets can be decoded.
In a more general case, where more than one packet is unknown by one or more sinks, we need to transmit a number of packets that, along with the subspaces spanned by the packets of sinks  , span the whole
, span the whole  . Transmitting
. Transmitting  linear combinations of packets is sufficient to achieve this goal.
linear combinations of packets is sufficient to achieve this goal.
In Figure 12, an example is given which clarifies the concept just described. In the setup the three sinks have three distinct subsets of packets and channels from  to each of the sinks have SNRs
to each of the sinks have SNRs  ,
,  and
and  . Table 2 gives a possible scheduling and transmission solution for the setup in Figure 12 by applying the method we just described together with channel adaptation.
. Table 2 gives a possible scheduling and transmission solution for the setup in Figure 12 by applying the method we just described together with channel adaptation.
 indicates the transmission phase. Each phase corresponds to the complete transmission of a native packet (or a sum of native packets).
indicates the transmission phase. Each phase corresponds to the complete transmission of a native packet (or a sum of native packets).
In the setup the three sinks have three distinct subsets of packets in  's buffer and channels from
's buffer and channels from  to each of the sinks have a different SNR.
to each of the sinks have a different SNR.
In particular, during the transmission the source broadcasts a packet obtained by adding packets  ,
,  , and
, and  , where
, where  is packet
is packet  after channel encoding adapted to
after channel encoding adapted to  . Once sink
. Once sink  receives
receives  , it needs packet
, it needs packet  . Next packet transmitted by
. Next packet transmitted by  is
is  added with
added with  and
and  for sinks
for sinks  and
and  , respectively. Finally packet
, respectively. Finally packet  is transmitted to sink
is transmitted to sink  .
.
7.2. Packet Fragmentation and Fairness
Our proposed solution implicitly assumes that native packets can be fragmented. Each native packet  can be considered as a length
can be considered as a length  buffer. In order to match the optimal rate on the channel, only a part of the buffer
buffer. In order to match the optimal rate on the channel, only a part of the buffer  is sent over the channel during a time slot on size
is sent over the channel during a time slot on size  coded packet. In the following, we discuss how to handle native packet fragmentation at the network level.
coded packet. In the following, we discuss how to handle native packet fragmentation at the network level.
Scheduling in Packet Fragmentation
When a node requests a packet that needs to be fragmented the first part of the packet is always sent out first. This avoids that different nodes in the network have nonoverlapping parts of the same native packet, which could make the formation of network coding groups more difficult. Let us now consider the case in which a given node  requests a fragment
requests a fragment  of a given native packet
of a given native packet  . In this case, nodes belonging to its NC group do not need to know the whole native packet. It is sufficient that the portion they know of native packet
. In this case, nodes belonging to its NC group do not need to know the whole native packet. It is sufficient that the portion they know of native packet  include fragment
include fragment  .
.
Capacity and NC Group Limits
The maximum rate at which a given node in a network group can receive data is actually limited by two factors. One is the capacity of the physical link between source and node (capacity-limited rate). The other factor that limits the transmission rate is the minimum across the nodes of the NC group of the portion of packet  . If such portion has length
. If such portion has length  , then the maximum transmission rate for packet
, then the maximum transmission rate for packet  during a packet slot must be less than
during a packet slot must be less than  , otherwise not all nodes in the NC group will be able to correctly decode the packet addressed to them (NC group-limited rate). The last factor must be taken into account in the formation of the NC group. In order to avoid such situation we can impose that a packet cannot be transmitted before it has been completely received.
, otherwise not all nodes in the NC group will be able to correctly decode the packet addressed to them (NC group-limited rate). The last factor must be taken into account in the formation of the NC group. In order to avoid such situation we can impose that a packet cannot be transmitted before it has been completely received.
Fairness Improvement
Shadowed users in a network would probably experience a high packet loss rate. The CIR approach penalizes those nodes, as their channels will have a low capacity. By adapting the rate to each of the nodes' channel conditions we can guarantee that users which experience shadowing for a long time (e.g., because of big urban barriers) are not totally excluded from the communication. This is likely to increase fairness and decrease delay in the system.
These are some side effects at network level of our proposed method. The global behavior of a network in terms of aggregated throughput, reliability, delay, and fairness where such transmission scheme is used need to be quantified by means of analytical/numerical methods, and is beyond the scope of this paper.
8. Conclusion
In this paper we proposed a new approach for rate adaptation in opportunistic scheduling. Such approach applies channel adaptation techniques originally proposed for asymmetric TWRC communication to a network context. After system model definition at both packet level (network group) and physical level (channel statistics), we described previously proposed methods for transmission scheduling in NC. We carried out a comparison between our method (adaptive information rate) and the scheduling method typically used in nc (constant information rate) from a information theoretical point of view. We obtained expression for the cdf of achievable rates for CIR system and a lower bound for AIR system's cdf. We also calculated an approximation to AIR cdf at low SNRs and showed that cdf of CIR systems is an upper bound that of AIR system. We implemented a simulator using nonbinary LDPC codes developed in the DaVinci project [17] and showed that our method allows a better exploitation of good channels with respect to CIR method. This was shown to increase throughput at each transmission. We then discussed some issues that arise from the modifications at physical level brought from AIR method in a network coding scenario. Such issues will be extensively analyzed and their impact quantified in our future works, as well as a system-level throughput analysis gain. New coding techniques can also be investigated in order to fully exploit achievable throughput and fairness enhancements in AIR systems.
References
Ahlswede R, Cai N, Li S-YR, Yeung RW: Network information flow. IEEE Transactions on Information Theory 2000, 46(4):1204-1216. 10.1109/18.850663
Fragouli C, Soljanin E: Network coding fundamentals. Foundations and Trends in Networking 2007, 2(1):1-133. 10.1561/1700000004
Lun DS, Médard M, Koetter R, Effros M: On coding for reliable communication over packet networks. Physical Communication 2008, 1(1):3-20.
Shannon CE: A mathematical theory of communication. The Bell System Technical Journal 1948, 27: 379-423, 623–656.
Ford LR Jr., Fulkerson DR: Flows in networks. United States Air Force Project RAND; August 1962.
Ho T, Koetter R, Médard M, Karger DR, Effros M: The benefits of coding over routing in a randomized setting. Proceedings of the IEEE International Symposium on Information Theory (ISIT '03), June-July 2003 442.
Ho T, Médard M, Koetter R, Karger DR, Effros M, Shi J, Leong B: A random linear network coding approach to multicast. IEEE Transactions on Information Theory 2006, 52(10):4413-4430.
Park J-S, Gerla M, Lun DS, Yi Y, Médard M: CodeCast: a network-coding-based ad hoc multicast protocol. IEEE Wireless Communications 2006, 13(5):76-81.
Katti S, Rahul H, Hu W, Katabi D, Medard M, Crowcroft J: XORs in the air: practical wireless network coding. IEEE/ACM Transactions on Networking 2008, 16(3):497-510.
Yomo H, Popovski P: Opportunistic scheduling for wireless network coding. IEEE Transactions on Wireless Communications 2009, 8(6):2766-2770.
Gong S-L, Kim B-G, Lee J-W: Opportunistic scheduling and adaptive modulation in wireless networks with network coding. Proceedings of the 69th IEEE Vehicular Technology Conference (VTC '09), April 2009 1-5.
Effros M, Medard M, Ho T, Ray S, Karger D, Koetter R: Linear network codes: a unified framework for source, channel, and network coding. Proceedings of the DIMACS Workshop on Network Information Theory, 2003
Hausl C: Improved rate-compatible joint network-channel code for the two-way relay channel. Proceedings of the Joint Conference on Communications and Coding (JCCC '06), March 2006, Sölden, Austria
Hou J, Hausl C, Kötter R: Distributed turbo coding schemes for asymmetric two-way relay communication. Proceedings of the 5th International Symposium on Turbo Codes and Related Topics, September 2008 237-242.
Tuncel E: Slepian-Wolf coding over broadcast channels. IEEE Transactions on Information Theory 2006, 52(4):1469-1482.
Cover TM, Thomas JA: Elements of Information Theory. Wiley-Interscience, New York, NY, USA; 1991.
Pfletschinger S, Mourad A, López E, Declercq D, Bacci G: Performance evaluation of non-binary LDPC codes. Proceedings of the ICT Mobile Summit, June 2009, Santander, Spain
Chou PA, Wu Y, Jain K: Practical network coding. Proceedings of the 51st Allerton Conference on Communication, Control and Computing, October 2003
Acknowledgments
The authors would like to thank Dr. Deniz Gunduz for the helpful discussions made during the development of present work. This work was partially supported by the Spanish Government through Project m:VIA (TSI-020301-2008-3), by the European Commission by INFSCO-ICT-216203 DaVinci (Design And Versatile Implementation of Nonbinary wireless Communications based on Innovative LDPC Codes) and the Network of Excellence in Wireless COMmunications NEWCOM++ (Contract ICT-216715), and by Generalitat de Catalunya under Grant 2009-SGR-940. G. Cocco is partially supported by the European Space Agency under the Networking/Partnering Initiative.
Author information
Authors and Affiliations
Corresponding author
Appendices
In the following, we derive the calculation for the cumulative density function of the achievable rate for the system with constant information rate and the approximation for the cdf of the adaptive information rate system we proposed in this paper. We talk about achievable rates and not capacity as we are not optimizing with respect to power.
A. Constant Information Rate
Channel coefficients are i.i.d. exponentially distributed random variables with mean value  . Their marginal pdf is then
. Their marginal pdf is then

Let us sort channel coefficients of the  receivers in ascending order, namely,
receivers in ascending order, namely,

We will use round brackets to indicate variables sorted in ascending order, that is,  is the smallest among variables
is the smallest among variables  . As stated in Section 5, the cdf for the constant information rate system is given by:
. As stated in Section 5, the cdf for the constant information rate system is given by:

Let us introduce the following notation:

and finally

Using (A.5) in (A.3) we can write

where  is the cumulative distribution function of the variable
is the cumulative distribution function of the variable  calculated in point
calculated in point  . The function
. The function  is, by definition
is, by definition

Note that the smaller the variable  , the higher the multiplying coefficient
, the higher the multiplying coefficient  .
.
We can rewrite the (A.7) as

Let us indicate the event inside brackets as  . Figure 13 gives a graphical representation of event
. Figure 13 gives a graphical representation of event  .
.
Figure 13
Virtual representation of event A. Random variables  are sorted in ascending order in sequence
are sorted in ascending order in sequence  . According to the definition of event
. According to the definition of event  the
the  th variable must assume a value less or equal
th variable must assume a value less or equal  .
.
We can calculate the probability of event  by using the law of total probability
by using the law of total probability

where  are disjoint events partitioning the area of the sample space to which
are disjoint events partitioning the area of the sample space to which  belongs. Let us choose as
belongs. Let us choose as  the event "
the event " out of
out of  variables fall in the interval
variables fall in the interval  " for all
" for all  and putting
and putting  and
and  . The intersection with
. The intersection with  imposes on
imposes on  the further constraint
the further constraint

Let us give an example to clarify the definitions given up to now for the case with  nodes. We have two i.i.d. random variables
nodes. We have two i.i.d. random variables  and
and  . We sort them and call the smallest one
. We sort them and call the smallest one  and the biggest one
and the biggest one  . Event A is, by definition:
. Event A is, by definition:  . Events
. Events  , with
, with  are the following:
are the following:
-
(i)
 "2 variables fall in the interval
"2 variables fall in the interval  and 0 variables fall in the interval
and 0 variables fall in the interval  ";
"; -
(ii)
 "2 variables fall in the interval
"2 variables fall in the interval  and 0 variables fall in the interval
and 0 variables fall in the interval 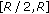 ";
"; -
(iii)
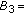 "1 variable falls in the interval
"1 variable falls in the interval  and 1 variable falls in the interval
and 1 variable falls in the interval 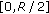 ".
".
 "2 variables fall in the interval
"2 variables fall in the interval  and 0 variables fall in the interval
and 0 variables fall in the interval 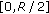 ";
"; "2 variables fall in the interval
"2 variables fall in the interval 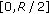 and 0 variables fall in the interval
and 0 variables fall in the interval 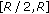 ";
";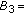 "1 variable falls in the interval
"1 variable falls in the interval  and 1 variable falls in the interval
and 1 variable falls in the interval 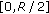 ".
".It is easy to see that these are disjoint events which partition the sample space, that is, they take into account all the possible ways in which the two variables can be distributed in the two intervals. In order to calculate the (A.9), we need to find the intersection between event  and each of the
and each of the  . It can be easily verified that such intersection can be found by adding to each
. It can be easily verified that such intersection can be found by adding to each  the constraint (A.10), which, for
the constraint (A.10), which, for  , can be expressed as "the number of variables that fall in the interval
, can be expressed as "the number of variables that fall in the interval  must be less than or equal to 1 and the number of variables that fall in the interval
must be less than or equal to 1 and the number of variables that fall in the interval  must be less than or equal to 2". This implies that the (A.9) is given by the sum of the probabilities of events
must be less than or equal to 2". This implies that the (A.9) is given by the sum of the probabilities of events  and
and  . Note that events
. Note that events  do not consider sorted variables, as the sorting is implicitly defined in the definition of such events. This allows to consider the variables as i.i.d, which makes calculation of events
do not consider sorted variables, as the sorting is implicitly defined in the definition of such events. This allows to consider the variables as i.i.d, which makes calculation of events  easier.
easier.
A similar calculation can be done for a generic number  of nodes. As seen in the example, the calculation reduces to defining events
of nodes. As seen in the example, the calculation reduces to defining events  , choose those which describe event
, choose those which describe event  and sum their probabilities. Such probabilities can be calculated as follows. The probability that a generic variable
and sum their probabilities. Such probabilities can be calculated as follows. The probability that a generic variable  (unsorted) falls in the interval
(unsorted) falls in the interval  is equal to
is equal to  ,
,  being the cumulative density function of
being the cumulative density function of  .
.  can be obtained transforming the exponential r.v.
can be obtained transforming the exponential r.v. 

where  is a function that assumes value 0 for
is a function that assumes value 0 for  , 1 for
, 1 for  and
and  in 0. Because of independency among the variables, we can calculate the probability that
in 0. Because of independency among the variables, we can calculate the probability that  variables fall in the interval
variables fall in the interval  , which is
, which is  . From now on, we will indicate with
. From now on, we will indicate with  the difference
the difference  . We can now express the probability of the union of events
. We can now express the probability of the union of events  with the formula (A.12)
with the formula (A.12)

where the coefficient  is the number of partitions of M elements in M bins putting
is the number of partitions of M elements in M bins putting  elements in bin number
elements in bin number  .Finally, including constraint (A.10) we obtain expression (A.13)
.Finally, including constraint (A.10) we obtain expression (A.13)

B. Adaptive Transmission
B.1. CDF in the Low SNR Regime Let us indicate with  the (unsorted) instantaneous capacity of the link between source and receiver
the (unsorted) instantaneous capacity of the link between source and receiver  . Let us recall from Section 5 that an achievable rate for such system is
. Let us recall from Section 5 that an achievable rate for such system is

We wish to calculate an approximation for the cdf of  in the low SNR regime. By definition the cdf of
in the low SNR regime. By definition the cdf of  is
is

where

 being an exponentially distributed random variable with mean value
being an exponentially distributed random variable with mean value  .
.
When  (which is the case most of the time in the SNR regime), we can approximate the logarithm with its Taylor expansion at the second term, that is
(which is the case most of the time in the SNR regime), we can approximate the logarithm with its Taylor expansion at the second term, that is

Thus, we have

Using expression (B.18) we can calculate the pdf of  as
as

By substituting the expression of  in (B.19) we find
in (B.19) we find

and finally:

At higher SNR the (B.24) is a loose lower bound for the cdf of  , in fact we have the following inequalities:
, in fact we have the following inequalities:



B.2. Upper Bound of cdf
We now show that the (16) upper bounds the cdf of the achievable rate for the AIR system. Let us start by modifying the condition in brackets in the (B.15) that we will call condition  . We relax such condition so that it be verified with higher probability for each
. We relax such condition so that it be verified with higher probability for each  . Such condition says that the sum of capacities in all links must not exceed
. Such condition says that the sum of capacities in all links must not exceed  . We want to find a condition
. We want to find a condition  so that if
so that if  is true also
is true also  is true, but there must exist a set of events with non zero probability for which if
is true, but there must exist a set of events with non zero probability for which if  is verified
is verified  is not. For this purpose, let us put
is not. For this purpose, let us put  , where
, where  is the event that defines the cdf of cir system (see Appendix ), that is
is the event that defines the cdf of cir system (see Appendix ), that is

Now it is sufficient to prove that the following two propositions are true


Let us start with the (B.26). For  to be verified, at least one of the
to be verified, at least one of the  must be
must be  R/
R/ because if not the sum in
because if not the sum in  would be greater than
would be greater than  . Moreover, if we impose that
. Moreover, if we impose that  for a given
for a given  , there must be at least another
, there must be at least another  such that
such that  . If this is not verified there will be
. If this is not verified there will be  for which
for which  plus
plus  , so the total sum would be greater than
, so the total sum would be greater than  . Iterating this
. Iterating this  times we will obtain exactly the condition
times we will obtain exactly the condition  which, as just shown, must be verified for the
which, as just shown, must be verified for the  to be true. Now let us consider the (B.27). We can take as condition
to be true. Now let us consider the (B.27). We can take as condition  the following:
the following:

It can be easily seen that  . The minimum value for the sum of all
. The minimum value for the sum of all  under condition
under condition  is
is  which is greater than
which is greater than  for
for  . This means that
. This means that  . We have left to show that
. We have left to show that  . The probability of
. The probability of  is a finite quantity given by
is a finite quantity given by

the  being the cdf of the random variable
being the cdf of the random variable  . We recall the expression for the
. We recall the expression for the 

B.3. Lower Bound
In order to find a lower bound for the cdf of AIR system, we introduce the following constraint to the condition inside brackets in the (B.15)

Adding (B.31) in (B.15) we obtain the following expression:

Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Cocco, G., Pfletschinger, S., Navarro, M. et al. Opportunistic Adaptive Transmission for Network Coding Using Nonbinary LDPC Codes. J Wireless Com Network 2010, 517921 (2010). https://doi.org/10.1155/2010/517921
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/517921