- Research
- Open access
- Published:
On stream selection for interference alignment in heterogeneous networks
EURASIP Journal on Wireless Communications and Networking volume 2016, Article number: 80 (2016)
Abstract
This paper proposes a stream selection algorithm to deal with the interference and increase the sum capacity in the context of heterogeneous networks where cells of different types coexist. Due to the different transmit powers between the macro and small cells, interference levels are also different. Since the small cells are densely deployed, fully connected interference network between small cells is considered in this paper. The proposed algorithm performs the selection of a stream sequence among a predetermined set of sequences. Those selected sequences are the ones that mostly contribute to the sum rate when performing the exhaustive search. As a consequence, since the search space is reduced, the complexity is significantly decreased. These stream sequences form a regular structure where the first stream is associated to a pico user. Another distinguishing property of the proposed approach is that the stream sequences include at least one stream for each user. When selecting the streams, the channel matrices of the unselected streams are projected orthogonally to the virtual transmit and virtual receive channels of the selected stream in order to align the interference in the null space of these virtual channels. The performance evaluations are carried out by considering different scenarios with different numbers and locations of pico cells. It is shown that the proposed method can significantly reduce the computational complexity while achieving a very close performance to the exhaustive search.
1 Introduction
Interference alignment (IA) is one of the techniques to effectively mitigate interference in wireless networks [1]. It is introduced as a linear precoding technique that aligns the interfering signals in time, frequency, or space. The key idea is to align the interfering signals into one-dimensional subspace at each receiver by designing precoding and postcoding vectors, so that the desired signal can be obtained in the interference-free signal subspaces.
IA studies started with a focus on K pair interference channels where each transmitter has a message for only one of the receivers. One family of approaches is based on investigating IA solutions in the form of closed-form expressions [2]. However, such analytical solutions are difficult to obtain for large-scale networks when the number of variables is higher than the number of equations in the network configuration [3]. The analysis given in [4] has shown that the capacity of the network linearly grows as the size of the network increases without any bound by using symbol extensions for K user multiple input multiple output (MIMO) interference channel with M antennas at each node. Although the capacity can increase linearly with K users even if the number of antennas is limited, symbol extension is difficult to adopt in practical systems. In the absence of symbol extension, it has been shown that the maximum achievable degrees of freedom (DoF) for K user MIMO interference channel with M transmit antennas and N receive antennas can be \(\frac {K(M+N)}{K+1}\) [5].
Since finding the closed-form IA solutions can be difficult for large networks, distributed IA approaches based on iterative schemes are more suitable and practicable [6]. MIMO IA precoders and postcoders are iteratively designed where, at each iteration, users try to minimize the interference leakage, i.e., the signal leakage into the desired signal subspaces by the other users. In addition, an iterative algorithm that maximizes per stream signal-to-interference-plus-noise ratio (SINR) called max-SINR is discussed. The disadvantage of iterative approaches is that they generally require many iterations as shown in the study of [7] where max-SINR [6] is extended for the cellular networks.
Stream selection-based IA approaches are inspired from user selection problems [8, 9]. Furthermore, user selection, antenna selection, and antenna switching have been studied to improve the performance of interference alignment in wireless networks [10–13]. The main idea of the stream selection has been initially implemented in [14] to design the precoding vectors for multi-user MIMO broadcast channel. Different stream selection approaches have been extended to interference channels in [15]. In the first approach, only one stream sequence is constructed by successively selecting the strongest streams from the null spaces of the previously selected ones. The second approach has further improved the first approach by constructing different stream paths that are initialized by each possible stream. The selection process continues with the strongest streams until no more streams can be and the stream path with the highest sum rate among all the constructed paths is selected at the end. The stream selection-based IA algorithms are not iterative, since they perform IA by successively selecting the streams as long as the total sum rate increases.
All these studies have been dealing with homogeneous networks where all the base stations have the same transmit power and the same number of transmit antennas. On the other hand, heterogeneous networks are the next generation of networks since they provide coverage extension, higher capacity, and network availability [16]. However, interference is still one of the biggest challenges and its management is very crucial for efficient deployment of network elements and performance enhancement in certain areas. In heterogeneous networks, a large number of smaller cells with different power levels (micro, pico, or femto cells) are deployed in the coverage of conventional macro cells using the same spectrum. Therefore, in the context of heterogeneous networks, IA methods have been studied to handle the problems caused by the coexistence of macro and small base stations (BSs).
In [17], a spectral transmission scheme for femto cell networks, which includes an adaptive sub-band partitioning method and an adaptive IA transceiver, has been introduced. Another study focusing on femto cell networks has handled the uplink interference generated from the macro cell users to the femto BSs by aligning the received signals of macro cell users in the same subspace at each femto BS [18]. This uplink interference has been also alternatively handled by a user selection method [19]. In [20], a hierarchical IA has been given, where the beamforming matrices are sequentially determined for small and macro cells to mitigate the interference by simple closed-form mathematical formulations. Hierarchical IA has been extended for dense deployments of pico cells by a multi-stage alignment process with a decrease in per user capacity performance [21]. In [22], a stream selection algorithm has been developed for heterogeneous networks such that the interference is handled by an orthogonalization procedure on the hierarchically selected streams in a heterogeneous network that is composed of one pico cell and one macro cell. It has been shown that the DoF can be increased by exploiting the partial connectivity, i.e., by considering a subset of cross-channels between transmitters and receivers in the homogeneous networks [23]. Since small cells can be deployed in a random and distributed manner, both the partial and fully connected interference networks have been investigated for IA approach to increase the performance of heterogeneous networks in [24].
In this paper, stream selection-based IA methods are investigated for commonly used heterogeneous network configurations which include multiple pico cells deployed close to each other at the cell edge regions of a macro cell [25–27]. Therefore, a fully connected interference network between pico cells is considered where the interference between pico cells is very strong. In such networks, the best stream permutation achieving the highest sum rate can be found with exhaustive search. However, exhaustive search is too complex due to the large search space. Thus, the main goal of this study is to decrease this search space. To that end, we propose a stream selection algorithm which decreases the complexity significantly while keeping the performance relatively close to that of the exhaustive search. In this study, the stream selection-based IA scheme which is designed for homogeneous networks [15] has been extended for heterogeneous networks by considering a different stream selection method; the selection method is based on constructing a set of regular stream sequences derived according to the heterogeneous network characteristics. Also, the algorithm is designed in such a way that it guarantees selecting at least one stream from each user while mitigating the interference among the selected streams.
The contributions of this paper can be summarized as follows.
-
A novel IA algorithm for heterogeneous networks is presented. The proposed algorithm significantly decreases the search space by constructing stream sequences that mostly contribute to the sum rate in the exhaustive search. These stream sequences form a regular structure where the first stream is associated to a pico user since the average signal-to-noise ratio (SNR) of the pico users is higher than the macro user.
-
One of the main differences between the existing stream selection algorithms and the proposed algorithm is that at least one stream is allocated to each user and, thus, service is guaranteed to each user.
-
The effect of the imperfect channel is investigated for the proposed algorithm.
The rest of this paper is organized as follows. The system model is presented in Section 2. In Section 3, the proposed IA algorithm based on stream selection is explained and the exhaustive search is analyzed in Section 4. Then, the stream selection algorithm for heterogeneous networks is proposed and the limited feedback scheme is also presented in Section 5. In Section 6, the performance evaluations are given; and finally, the study is concluded in Section 7.
Notations: Rank (A) refers to the rank of the matrix A; (A)H represents the transpose conjugate of the matrix A and |A| is the determinant of square matrix A. Capital Greek letters such as Ω denote sets and |Ω| denotes the number of elements in Ω.
2 System model
In this study, a K-pair heterogeneous network is considered composed of pico cells and a macro cell. Each pair k has \(N_{T_{k}}\) transmitter antennas and \(N_{R_{k}}\) receiver antennas as shown in Fig. 1. For the sake of simplicity, macro BS - macro user pair is defined as the pair k=1, and pico BS - pico user pairs are kept in the set k∈Γ={2,…,K}. It is assumed that the required channel state information (CSI) is available at all transmitter and receiver sides.

System model for MIMO heterogeneous network
The channel matrix between transmitter j and receiver k with dimension \(N_{R_{k}} \times N_{T_{j}}\) is denoted as H kj . Each element of the channel matrix includes the effects of path loss, shadowing, and fading. The fading is modeled as an independent and identically distributed complex Gaussian random variable with \(\mathcal {CN}(0,1)\). Transmission channel matrices are represented by H kk and interference channel matrices are given by H kj (j≠k). The received signal at user k is
where, for each receiver k, n k is a \(N_{R_{k}} \times 1\) vector which each element of n k represents additive white Gaussian noise with zero mean and variance σ 2. T k is the precoding matrix of transmitter k with dimension \(N_{T_{k}} \times q_{k}\), and transmitter k can transmit using q k independent streams with q k ≤d k where \(d_{k} = \min (N_{R_{k}}, N_{T_{k}})\phantom {\dot {i}\!}\). s k is the symbol vector with dimension of q k ×1 and denoted as \(\phantom {\dot {i}\!}\mathbf {s}_{k} = [s_{k,1}\:\ldots \:s_{k,q_{k}}]^{T}\) where \(\mathbb {E}\left [\left \|\mathbf {s}_{k}\right \|^{2}\right ]=P_{k}\phantom {\dot {i}\!}\) and P k is the transmit power of BS k. In addition, the maximum total number of streams in the network is calculated as follows.
Each user decodes the received signals by multiplying them with the postcoding vectors, D k , of dimension \(q_{k} \times N_{R_{k}}\phantom {\dot {i}\!}\). Thus, the decoded data symbols are given by
The signal-to-noise-interference ratio (SINR) of stream i of receiver k is calculated as
where \(\mathbf {t}_{k}^{i}\) is the ith column vector of the precoding matrix T k with dimension \(N_{T_{k}} \times 1\), and \(\mathbf {d}_{k}^{i}\) is the ith column vector of postcoding matrix D k with dimension \(N_{R_{k}} \times 1\). Furthermore, B ki is defined as the interference plus noise covariance matrix for stream i of receiver k and it is given by
The sum rate (SR) is calculated as follows.
The main objective is to mitigate the interference while finding the best stream allocation scheme over the base station (BS) user pairs. The stream allocation scheme which maximizes the total sum rate of the network while guaranteeing at least one stream selection from each user can be formulated as follows.
3 Interference alignment procedure
Interference alignment solutions based on stream selection align the interference after each stream selection step. There are two kinds of interference between the streams. The first one is the interference from the selected stream to the unselected streams and the second one is the interference to the selected stream from the unselected streams. Therefore, two types of virtual channels are defined as virtual receiving channels (VRCs) and virtual transmitting channels (VTCs) [15]. VRCs, \(\mathbf {u}_{k^{*}}^{l^{*}H}\mathbf {H}_{k^{*}k}\phantom {\dot {i}\!}\), are the channel of user k ∗ seen from the transmitter side and VTCs, \(\mathbf {H}_{kk^{*}}\mathbf {v}_{k^{*}}^{l^{*}}\phantom {\dot {i}\!}\), are the channels of user k ∗ seen from the receiver side, where k ∗ is the user whose stream is just selected. For each selected stream, multiple VRCs and VTCs are designed by using the precoder and decoder vectors, respectively. These vectors are obtained from the singular value decomposition (SVD) procedure. Precoding and postcoding matrices are constructed from the precoding and postcoding vectors corresponding to the selected streams, and they are expressed as \(\phantom {\dot {i}\!}\mathbf {T}_{k^{*}} = \left [\mathbf {v}_{k^{*}}^{1}, \mathbf {v}_{k^{*}}^{2}, \ldots, \mathbf {v}_{k^{*}}^{q_{k}}\right ]\) and \(\mathbf {D}_{k^{*}} = \left [\mathbf {u}_{k^{*}}^{1}, \mathbf {u}_{k^{*}}^{2}, \ldots, \mathbf {u}_{k^{*}}^{q_{k}}\right ]\phantom {\dot {i}\!}\), respectively.
Therefore, after the virtual channels related to user k ∗ are obtained, the impact of this stream to the unselected streams is reduced by orthogonal projections. More precisely, the space spanned by the unselected potential beamformers of each user k≠k ∗ is projected orthogonally to the corresponding VRC and VTC of the selected stream belonging to user k. The orthogonal projection matrix parallel to vector x is calculated as \(\mathbf {P}_{\mathbf {x}}^{\bot } = \mathbf {I}-\frac {\mathbf {x}\mathbf {x}^{H}}{\left \|\mathbf {x}\right \|^{2}}\).
The vectors of the projected matrices \(\mathbf {H}_{kk}^{\bot }\), ∀k≠k ∗, are in the null space of all previously selected streams. At each iteration i, the interference from the unselected streams to the selected stream is reduced by projecting the channel matrices \(\mathbf {H}_{kk}^{\bot }\) orthogonally to the VRC and the interference to the unselected streams from the selected stream is reduced by projecting the channel matrices \(\mathbf {H}_{kk}^{\bot }\) orthogonally to the VTC. The reason for projecting all VTCs and VRCs of the unselected streams can be explained as follows. At the beginning, all streams are available for the selection. When a stream is selected, all channels of the unselected streams are orthogonally projected to both VTC and VRC of the selected stream. In this way, when another stream is to be selected, its channel is guaranteed to become orthogonal to the channels of the previously selected streams and, thus, it does not generate any interference to them.
The interference alignment procedure for each selected stream l ∗ of user k ∗ is summarized in Algorithm 1.

The worst-case computational complexity of Algorithm 1 is calculated as follows ([28, 29]).
where \(M = \max _{\forall k}(N_{T_{k}})\phantom {\dot {i}\!}\) and \(\phantom {\dot {i}\!}N = \max _{\forall k}(N_{R_{k}})\) are the maximum number of transmitter and receiver antennas, respectively.
4 Exhaustive search of the stream sequence selection
In this section, exhaustive search is described where all possible stream sequences constructed by different stream permutations are considered to find the best permutation based on the objective function given in Eq. (7a) with the constraint of allocating at least one stream per user given in Eq. (7b). Streams, stream sequences, and the related sets are defined as follows.
Streams are identified using the singular values which are computed from the SVD of all the channels, \(\mathbf {H}_{kk}=\mathbf {U}_{k}\mathbf {S}_{k}\mathbf {V}_{k}^{H}\phantom {\dot {i}\!}\) and each stream i can be expressed as \(\phantom {\dot {i}\!}\pi _{i} = \left (k_{i}, l_{i}\right) \;\text {where} \; \; k_{i} \in \left \{1, \ldots, K\right \}, \; l_{i} \in \left \{1, \ldots, q_{k_{i}}\right \} \; \text {and} \; i\in \left \{1,\ldots,r\right \}\). The set of all possible stream sequences can be defined as follows.
where Φ j is the set of all permutations of length j∈{1,…,r} given by
All stream sequences that include at least one stream from each BS user pair are kept in set Π which can be defined as follows.
In other words, π is a stream sequence of length j which is constructed by including at least one stream from each user k.
Since it is difficult to find the exact number of elements in set Π which satisfy the condition given in Eq. 7b, the maximum number of elements of set Π is calculated as follows.
For each sequence, streams are selected successively; the selection continues until no more streams can be selected and the selected streams are kept the in set Ψ. This procedure is summarized in Algorithm 2.

Using Algorithm 2, Algorithm 3 performs exhaustive search which tries all relevant stream sequences and finds the sequence that yields the highest sum rate.

The most challenging drawback of the exhaustive search is its complexity that depends on the number of streams. An upper bound on the number of calls to Algorithm 1 by the exhaustive search can be formulated as follows.
Since this brute force approach is too complex to implement in systems with sufficiently large number of streams, an approach that has a lower complexity and a performance close to the exhaustive search is required.
5 The proposed advanced successive stream selection
In this section, the proposed successive stream selection algorithm (ASNSSS) is explained in detail. The algorithm is developed by analyzing the data collected from extensive exhaustive searches. It performs the selection of a stream sequence among a predetermined set of sequences in order to reduce the complexity while satisfying the problem given in the Eqs. (7a) and (7b). This predetermined set is composed of the sequences with the highest probability of occurrence while performing the exhaustive search. We have shown that the sequences in this predetermined set have a regular structure which can be achieved by selecting the initial streams among the users that have higher SNR values. Consequently, the proposed stream selection approach starts with pico streams, because pico users are more likely to have higher SNR values on the average as justified in the Appendix. The construction of the stream sequences based on the regular structure is expressed as follows.
Generated stream sequences are kept in set Π A . In order to explain the construction of Π A , each pico user is associated with a series of stream sequence sets. More precisely, the following sets are constructed for each pico user k ′∈Γ
In other words, the set \(\Xi _{k'}\phantom {\dot {i}\!}\) includes stream sequences π which are composed of stream permutations of length \(d_{k'}\phantom {\dot {i}\!}\) that belong to pico user k ′. Therefore, the number of elements of \(\Xi _{k'}\phantom {\dot {i}\!}\) is \(\left |\Xi _{k'}\right | = d_{k'}!\phantom {\dot {i}\!}\)
Set \(\Upsilon _{k',h'}\phantom {\dot {i}\!}\) has two indices. Index k ′ is used to leave out the streams of pico user k ′ which are considered in construction of \(\phantom {\dot {i}\!}\Xi _{k'}\) and index h ′ is used to leave out the streams of pico user h ′ one of which is considered in construction of set \(\phantom {\dot {i}\!}\Delta _{h'}\). The number of elements of this set is calculated as follows.
Note that if |Γ|=2, \(\phantom {\dot {i}\!}\Upsilon _{k',h'}=\emptyset \).
Since set Λ only includes the strongest stream of the macro user, |Λ|=1.
In addition, the number of elements of this set is \(\left |\Delta _{h'}\right |=1\phantom {\dot {i}\!}\). That is to say, the set Δ includes the strongest stream of the remaining pico user.
Based on the above sets, Π A is constructed as follows.
Furthermore, the number of elements of set Π A is computed as follows.
While constructing set Π A , interference alignment is implemented after the selection of each stream. Following the selection of a stream sequence from Π A , it might still be possible to increase the sum rate further by adding more streams to the constructed stream sequences. This is realized by attempting to select the strongest streams from the set which is composed of the remaining unselected streams and defined as follows:
where \(\pi ^{*}_{A}\) is the sequence of the selected streams.
The whole procedure of the algorithm ASNSSS is explained in Algorithm 4.

Furthermore, an upper bound on the number of calls to Algorithm 1 performed by the proposed algorithm can be formulated as follows.
Limited feedback scheme for stream selection algorithms
A limited feedback scheme is also studied based on the channel quantization model for the proposed IA algorithm. A centralized feedback model is considered in which the macro BS receives all the channel direction information (CDIs) from pico BSs through the error- and delay-free backhaul links. Then, the precoding and postcoding vectors are computed by implementing the proposed algorithm using the collected CSIs at the macro BS.
In order to obtain the CDIs, codebooks are generated by using random vector quantization (RVQ) which contains \(2^{N_{d}}\phantom {\dot {i}\!}\) codewords, where N d is the number of bits. The codewords are independent and isotropically distributed over the unit sphere. The CDI is calculated by normalizing the channel matrix between transmitter i and receiver k using its Frobenius norm as \(\phantom {\dot {i}\!}\bar {\mathbf {H}}_{ki} = \frac {\mathbf {H}_{ki}}{\left \|\mathbf {H}_{ki}\right \|_{F}}\). In addition, it is assumed that the channel gain, ∥H ki ∥ F , is perfectly known at all the transmitters and receivers. The quantization procedure can be detailed as follows.
-
The normalized channel matrix, \(\bar {\mathbf {H}}_{ki}, \; \forall k,\; \forall i\), is vectorized as \(\bar {\mathbf {h}}_{ki} = vec(\bar {\mathbf {H}}_{ki})\) where \(\bar {\mathbf {h}}_{ki}\in \mathbb {C}^{N_{T_{k}}N_{R_{k}}\times 1}\).
-
The codebook is generated using RVQ as \(\mathbf {C}_{k} = \left \{\mathbf {c}_{k}^{1} \ldots \mathbf {c}_{k}^{c} \ldots \mathbf {c}_{k}^{2^{N_{d}}}\right \}\) where \(\left \|\mathbf {c}_{k}^{c}\right \|=1\) for ∀c and \(\mathbf {c}_{k}^{c} \in \mathbb {C}^{N_{T_{k}}N_{R_{k}}\times 1}\).
-
The codeword \(\mathbf {c}_{k}^{j*}\) that minimizes the Chordal distance metric is chosen by
$$\begin{array}{@{}rcl@{}} {\mathbf{c}_{k}^{j*} = \text{min}\; d\left(\bar{\mathbf{h}}_{ki}, \mathbf{c}_{k}^{j}\right)} \end{array} $$((22))where \(d\left (\bar {\mathbf {h}}_{ki}, \mathbf {c}_{k}^{j}\right) = \sqrt {1-\left |\bar {\mathbf {h}}_{ki}^{H} \mathbf {c}_{k}^{j}\right |^{2}}\). The selected codeword, \(\mathbf {c}_{k}^{j*}\), can be also called quantized unit vector channel and denoted as \(\tilde {\bar {\mathbf {h}}}_{ki}\).
-
Then, \(\tilde {\bar {\mathbf {h}}}_{ki}\) is reshaped as \(\tilde {\bar {\mathbf {H}}}_{ki} \in \mathbb {C}^{N_{R_{k}} \times N_{T_{k}}}\).
-
Accordingly, the quantized channel, \(\tilde {\mathbf {H}}_{ki}\), is determined as \(\tilde {\mathbf {H}}_{ki}=\tilde {\bar {\mathbf {H}}}_{ki}\times \left \|\mathbf {H}_{ki}\right \|_{F}\).
The amount of the feedback load is K 2×N d .
6 Performance results
Performance results of the proposed algorithm are compared with the existing stream selection algorithms such as successive stream selection and enhanced successive stream selection [15] and iterative algorithms, such as max-SINR and min-Leakage [6]. Therefore, before giving the details of the performance results, existing stream selection algorithms are briefly explained as follows.
6.1 Existing stream selection algorithms
-
Successive stream selection approach (SNSSS): Only one stream sequence is constructed by successively selecting the streams having the highest singular values, i.e., strongest streams. During this selection, the sum rate contributions of these streams are checked to see whether or not they increase the system throughput. Thus, the stream which has the highest singular value and which increases the sum rate is chosen at each selection step. Although this algorithm has a very low complexity, it is a suboptimal solution due to the searching of only one stream sequence which is one of the stream sequence provided by the exhaustive search. Therefore searching more stream sequences gives better throughputs with the cost of higher complexities. The complexity in terms of the number of calls to Algorithm 1 by SNSSS is r.
-
Enhanced successive stream selection (ESNSSS): In order to prevent such a suboptimal solution as in SNSSS approach, ESNSSS constructs different stream sequences each of which has a different initial stream. In this way, it constructs multiple stream sequences, each of which starts with a different stream and selects the sequence which achieves the highest sum rate. The complexity in terms of the number of calls to Algorithm 1 by ESNSSS is r 2.
Since the main objective is to guarantee that at least one stream from each user is selected, in the simulations, existing stream selection algorithms are modified to satisfy the guaranteed service property. It is achieved by performing the selection procedure with the maximum singular value which increases the sum rate. If such a stream cannot be found, a stream that causes the minimum sum rate decrease is selected for a user with no selected streams.
In order to study the performance results of the proposed algorithm, multiple pico cells are deployed at the cell edge regions under the coverage of a macro cell. System behavior is observed by changing the locations of the pico BSs with respect to macro BS. More precisely, pico BSs are initially placed relatively close to the macro BS and they are shifted together with the pico users from the inner area to cell edge area of the macro BS which is fixed at location (0,0). Locations of the pico cells are identified using as the ratio d/R where R is the macro cell radius and d is the distance between the macro BS and each pico BS. Since, in practice, pico cells are generally deployed closer to the cell edge areas of the macro cells, the ratio ranges from 0.6 to 1. In addition, the interference level between pico cells generated to each other is investigated by changing the distance between the pico cells, L, while d/R is fixed.
Simulations are carried out using the system parameters listed in Table 1.
6.2 Different scenarios
There are 4 different scenarios to evaluate the performance of the proposed algorithm in the following sections. In scenarios A and B, 2 pico cells are deployed at the cell edge regions of the macro cell as illustrated in Fig. 2. There are 2 transmit antennas for each pico cell and 4 transmit antennas for the macro cell. Each cell has one user that is randomly placed inside its coverage area and there are 2 receive antennas at each user. If the distance between the macro user and any pico cell is at most 250 m, the macro user receives nonnegligible interference from the pico BSs. Therefore, the interference alignment algorithm, Algorithm 1, is applied to mitigate the generated interference from pico BSs to the macro user.

Scenarios A and B. 2 pico cell cases with different values of d and L
In scenarios C and D, 3 pico cells are symmetrically deployed with respect to the macro cell as illustrated in Fig. 3. The number of \(N_{T_{k}}\) and \(N_{R_{k}}\) are the same as in scenarios A and B for each pico cell and for macro cell.

Scenarios C and D. 3 pico cell cases with different values of d and L
The proposed algorithm achieves to compose the set of stream sequences having a regular structure by examining certain metric values obtained from the exhaustive analyses. These metrics are P, SR and P×S R as shown in the stream trees, such as in Fig. 4 and can be defined as follows.
-
P is the selection probability of each stream sequences.
Fig. 4 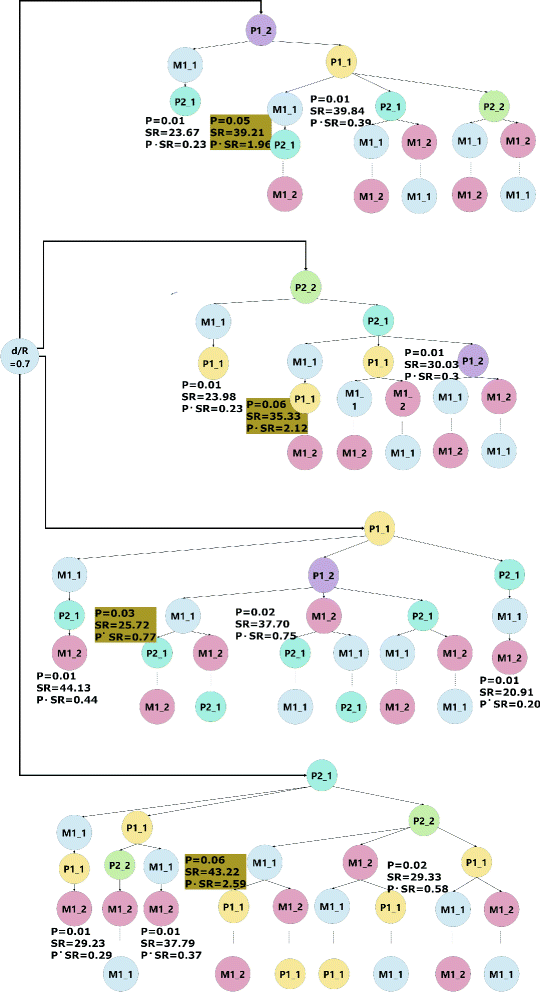
Scenario A. Exhaustive analysis as stream tree
-
SR is the average of the sum rates achieved by the sequence only when the sequence is selected.
-
The multiplication of P and SR represents the sum rate contribution of the selected stream sequence.

6.2.1 Scenario A: d/R is changing while L is fixed
In the first case of scenario A, pico cells are shifted towards to the cell edge of the macro cell by changing the ratio d/R. The distance between the pico cells, L, is set to 150 m. First, to see the construction of the stream sequence set in the proposed approach, the selected stream sequences in the exhaustive search are analyzed by examining metrics P, SR and P×S R. The analyses show that different stream sequences with different number of streams can be selected by the exhaustive search. The tree of the selected stream sequences starting from pico streams, such as the two streams of pico 1 user are P1_1, P1_2 and the two streams of pico 2 user are P2_1, P2_2, can be seen in Fig. 4 for d/R=0.7. The stream sequences constructed by the proposed algorithm as described in Section 5 are highlighted in the tree. The selected streams starting from macro streams, M_1 and M_2, have lower sum rate contributions, so that they are not shown in this tree due to the limited space of the paper.
Examining the highlighted data in the predetermined set which are constructed by the proposed approach, it can be seen that the sum rate contribution of the selected stream sequences (P×S R) are higher than the other selected sequences in the exhaustive search. This observation can be used to achieve very high sum rate values while decreasing the size of the search tree. The tree obtained through the proposed algorithm confirms this property. For example, Fig. 5 shows that it is possible to shrink the tree in Fig. 4 while still achieving high sum rate values.

Scenario A. Stream sequences constructed by ASNSSS
The sum rate values achieved by different approaches are given in Fig. 6. It can be seen that ASNSSS outperforms the existing stream selection methods and iterative approaches while reaching the performance of the exhaustive search.

Scenario A. Sum rate vs d/R between 0.6 and 1
The comparison of the number of selected streams for each user considering different distance ratios can be given in Table 2. The results confirm that the proposed method allocates more streams to pico users at the cell edge regions while increasing the sum rate.
Moreover, the performance of the stream selection algorithms with the quantized CSI using N d =7 bits for each channel are compared in Fig. 7. It can be seen that ASNSSS can achieve higher performance results than the existing stream selection algorithms.

Scenario A. Sum rate with imperfect CSI vs d/R between 0.6 and 1
6.2.2 Scenario B: d/R is fixed while L is changing
In this scenario, x-axis is fixed at the cell edge of the macro cell, while pico cells are shifted away from each other along the y-axis. The distance between the pico cells is kept maximum L=400 m to ensure a fully connected network. Since the interference generated between the pico cells beyond this distance is very weak, there is no need to perform interference alignment algorithm between pico cells.
Figure 8 shows the performance comparison between the proposed algorithm and the existing algorithms. It can be seen that the gap between the exhaustive search and the proposed ASNSSS algorithm is very small, only approximately 1.3 bps/Hz; and ASNSSS outperforms the existing stream selection methods and iterative approaches.

Scenario B. Sum rate vs distance L between 100 and 400 m
6.2.2.1 Complexity comparison of the stream selection algorithms for scenario A and scenario B
The complexity of the stream selection algorithms are calculated in terms of the number of calls to Algorithm 1 and the comparison is given in Table 3 for scenarios A and B, since the total number of streams is the same in scenarios with the same network configurations. It can be observed that Algorithm 1 is called by ASNSSS at most 24 times which is much fewer than invocations performed by exhaustive search and also ESNSSS. It should be noted that these results represent upper bounds for the given algorithms (see Eq. (21)), since different stream sequences with different lengths can be selected by the stream selection algorithms. In the exhaustive search, although the number of the searched stream sequences is fixed, it is difficult to obtain the exact number of the stream sequences and, thus, the exact number of calls to Algorithm 1 due to the constraint defined in Eq. (7b) (See Eq. (13)). Therefore, an upper bound is also calculated for the exhaustive search.
Furthermore, simulations are performed to compute the number of calls to Algorithm 1 at d/R=0.8 and L=150 m and the histograms are given for SNSSS, ASNSSS, and ESNSSS in Fig. 9. The number of calls to Algorithm 1 is fixed which is equal to 9216 in the exhaustive search. In addition, the average number of calls to Algorithm 1 does not change with either d/R or L. The results demonstrate that ASNSSS has a lower complexity with a simple regular structure when compared to the other algorithms.

Comparisons of the average number of calls to Algorithm 1 at d/R= 0.8 and L= 150 m for scenarios A and B
6.2.3 Scenario C: d/R is changing while L is fixed
In this scenario, pico cells are shifted towards to the cell edge of the macro cell by changing the ratio d/R while the distances between the pico cells are kept fixed as L=200 and S=200 m. Once again, the tree of the selected streams in the exhaustive search is used to determine the set of stream sequences having a regular structure with higher sum rate contributions. The data collected from exhaustive search as in the previous scenarios indicates that the stream sequences constructed by the proposed algorithm have large contributions to the total sum rate. There are 24 stream sequences generated based on a regular structure described in Section 5 for the scenarios with 3 pico cells.
The sum rate values achieved by different approaches for the first case of this scenario are given in Fig. 10. It is shown that the performance of the proposed algorithm is quite close to that of the exhaustive search; and the gap is approximately 1 bps/Hz. Additionally, ASNSSS shows better performance than the other existing stream selection approaches such as ESNSSS and SNSSS.

Scenario C. Sum rate vs d/R between 0.6 and 0.9
6.2.4 Scenario D: d/R is fixed while L is changing
In this scenario, pico cells 2 and 3 are shifted away from each other along the y-axis and fixed along the x-axis where d/R=0.7 while pico cell 1 is fixed.
The performances of the proposed and the existing algorithms for this case is shown in Fig. 11. Similar to the previous cases, the performance of the proposed algorithm is quite close to that of the exhaustive search; and the gap is approximately 1 bps/Hz while its performance is better than the other existing algorithms.

Scenario D. Sum rate vs distance L between 100 and 400 m
6.2.4.1 Complexity comparison of the stream selection algorithms for scenario C and scenario D
To evaluate the complexities, once again, the number of calls to Algorithm 1 is considered for scenarios C and D. To compute the maximum number of calls to Algorithm 1, Eqs. (13) and (21) are used and the results are given in Table 4. It is shown that there is a significant performance reduction with ASNSSS from a practical point of view and exhaustive search becomes impractical when compared to ASNSSS. Also, although ESNSSS and SNSSS algorithms have lower complexities, ASNSSS can achieve almost the same performance with the exhaustive search. Furthermore, histograms of the number of calls to Algorithm 1 are obtained for SNSSS, ASNSSS, and ESNSSS as seen in Fig. 12 for d/R=0.8 and L=150 m. The number of calls to Algorithm 1 is fixed which is equal to 729,216 in the exhaustive search. In addition, the average number of calls to Algorithm 1 does not change with either d/R or L.

Comparisons of the average number of calls to Algorithm 1 at d/R= 0.8 and L= 150 m for scenarios C and D
The results demonstrate a clear advantage of ASNSSS in terms of complexity and applicability due to the fact that ASNSSS avoids from searching all stream paths by making use of a simple regular structure.
7 Conclusions
In this paper, we have presented an efficient stream selection approach for heterogeneous networks in order to reduce the complexity of the exhaustive search and, still, achieve a close performance. The proposed algorithm deals with the interference among different macro and pico cells; after each stream is selected, it performs orthogonal projections in order to handle the interference to and from the selected stream. Furthermore, it satisfies the constraint that at least one stream must be allocated to each user, which is not enforced by the existing stream selection approaches.
The proposed solution selects the best stream sequence in terms of sum rate from a predetermined set of sequences that is constructed by analyzing extensive searches. It is observed that initializing the stream sequences using the streams of pico users generally leads to better stream sequences since it is more likely for pico users to have a higher SNR value than the macro user.
The performance of the algorithm has been evaluated for different scenarios with different number of pico cells by varying the positions of pico BSs at the cell edge zone of the macro cell. The performance results indicate that the proposed algorithm outperforms the existing stream selection approaches and iterative IA solutions by getting closer to the upper bound set by the exhaustive search while achieving a significantly lower complexity. The proposed approach can be extended to multiuser heterogeneous networks as a future work.
8 Appendix
Justification for the initialization of stream sequences with pico user streams
Although the collected data do not yield a complete criterion for step-by-step selection of each stream, it is possible and important to justify the selection of pico streams as the initial streams. The data show that stream paths leading to relatively higher sum rate values generally start with the streams of the user who has the greatest SNR value. Below, it is justified that with high probability, this user is a pico user.
Let \(\rho _{p}= \frac {P_{r_{p}}}{P_{n}}\) and \(\rho _{m}= \frac {P_{r_{m}}}{P_{n}}\) be the average SNR values of pico and macro users, respectively. Furthermore, let \(P_{r_{p}}=P_{t_{p}}(dB) - P_{L_{p}}(dB)\) and \(P_{r_{m}}=P_{t_{m}}(dB) - P_{L_{m}}(dB)\) be the received powers of the corresponding pico and macro users, respectively, where \(P_{L_{p}}\) and \(P_{L_{m}}\) are the path loss for pico and macro users, and \(P_{t_{p}}\) and \(P_{t_{m}}\) are the transmitted powers of the corresponding pico and macro BSs, respectively. Also, P n is the noise power.
In order to find the probability that the SNR of the pico user is greater than the SNR of the macro user, P(ρ p >ρ m ), the following probability can be considered.
Using the path loss equations given in Table 1 in Section 6, which are some of the most commonly employed path loss models in the heterogeneous network scenarios [26, 30], the following can be performed.
where r p is the distance between the pico user and the pico BS and r m is the distance between the macro user and its BS. In addition, it is assumed that 37.6/36.7≈1. For heterogeneous networks, pico transmit power, \(P_{t_{p}}\), can range from 23 to 30 dBm and typical macro transmit power, \(P_{t_{m}}\), is 43 dBm. Therefore, the probability of \(P(\frac {r_{p}}{r_{m}} \leq K)\) can vary between 0.12 to 0.2. In this study, K is 0.1377 because \(P_{t_{p}}\) is 24 dBm.
In order to calculate the probability that \(P(\frac {r_{p}}{r_{m}} \leq K)\), let X be the random variable to represent the distance of the pico user to its pico cell and Y be the random variable to represent the distance of the macro user to its macro cell. These random variables are independent and the cumulative distribution functions of X and Y are given as follows [31].
where R p is the range of a pico BS and R m is the range of a macro BS. Consequently, the probability density functions of X and Y are as follows.
To calculate the probability that \(P(\frac {r_{p}}{r_{m}} \leq K)\), a new random variable Z=X/Y can be used as follows [31].
Since x∈[0,R p ] and y∈[0,R m ],
where F X (x)=1 if x>R p . For z>R p /R m ,
If Z=K=0.1377, R p =0.1 k m, and R m =1 k m, then
Thus, a pico user has a higher SNR value than a macro user with a probability of 73.6 %. Note that these derivations are obtained for K p =1. For cases K p =L, then the probability of having higher SNR values for pico users becomes as follows.
Therefore, pico users have higher SNR values than a macro user with a probability of 92.7 % in scenario A and 98 % in scenario B.
References
SA Jafar, Interference alignment: a new look at signal dimensions in a communication network. Found. Trends. Commun. Inf. Theory. 7(1), 1–136 (2011).
VR Cadambe, SA Jafar, in Communications, 2008. ICC ’08. IEEE International Conference On. Interference alignment and spatial degrees of freedom for the K-user interference channel, (2008), pp. 971–975, doi:http://dx.doi.org/10.1109/ICC.2008.190.
CM Yetis, T Gou, SA Jafar, AH Kayran, On feasibility of interference alignment in MIMO interference networks. Signal Process. IEEE Transac.58(9), 4771–4782 (2010). doi:http://dx.doi.org/10.1109/TSP.2010.2050480.
VR Cadambe, SA Jafar, Interference alignment and degrees of freedom of the K-user interference channel. Inf. Theory. IEEE Transac.54(8), 3425–3441 (2008). doi:http://dx.doi.org/10.1109/TIT.2008.926344.
M Razaviyayn, G Lyubeznik, Luo Zhi-Quan, On the degrees of freedom achievable through interference alignment in a MIMO interference channel. Signal Process. IEEE Transac.60(2), 812–821 (2012). doi:http://dx.doi.org/10.1109/TSP.2011.2173683.
K Gomadam, VR Cadambe, SA Jafar, A distributed numerical approach to interference alignment and applications to wireless interference networks. Inf. Theory. IEEE Transac.57(6), 3309–3322 (2011). doi:http://dx.doi.org/10.1109/TIT.2011.2142270.
J Schreck, G Wunder, Distributed interference alignment in cellular systems: analysis and algorithms. Sustain. Wirel. Technol. (European Wireless), 1–8 (2011).
T Yoo, A Goldsmith, On the optimality of multiantenna broadcast scheduling using zero-forcing beamforming. Sel Areas Communications, IEEE Journal on. 24(3), 528–541 (2006). doi:http://dx.doi.org/10.1109/JSAC.2005.862421.
L Sun, MR McKay, Eigen-based transceivers for the MIMO broadcast channel with semi-orthogonal user selection. Signal Process. IEEE Trans.58(10), 5246–5261 (2010). doi:http://dx.doi.org/10.1109/TSP.2010.2053709.
N Zhao, FR Yu, H Sun, A Nallanathan, H Yin, A novel interference alignment scheme based on sequential antenna switching in wireless networks. Wirel. Commun IEEE Trans.12(10), 5008–5021 (2013). doi:http://dx.doi.org/10.1109/TWC.2013.090413.121731.
N Zhao, FR Yu, VCM Leung, Opportunistic communications in interference alignment networks with wireless power transfer. IEEE Wirel. Commun.22(1), 8895 (2015). doi:http://dx.doi.org/10.1109/MWC.2015.7054723.
H Gao, Y Ren, C Yuen, T Lv, in Globecom Workshops (GC Wkshps), 2013 IEEE. Distributed scheduling achieves the optimal multiuser diversity gain for MIMO-Y channel, (2013), pp. 7–12, doi:http://dx.doi.org/10.1109/GLOCOMW.2013.6824.
Hui Gao, Chau Yuen, HA Suraweera, Lv Tiejun, in Communications (ICC), 2013 IEEE International Conference on. Multiuser diversity for MIMO-Y channel: max-min selection and diversity analysis, (2013), pp. 5786–5791, doi:http://dx.doi.org/10.1109/ICC.2013.6655519.
M Amara, D Slock, Y Yuan-Wu, in Signal Processing Advances in Wireless Communications (SPAWC), 2011 IEEE 12th International Workshop On. Near capacity linear closed form precoder design with recursive stream selection for MU-MIMO broadcast channels, (2011), pp. 336–340, doi:http://dx.doi.org/10.1109/SPAWC.2011.5990425.
M Amara, M Pischella, D Le Ruyet, Enhanced stream selection for sum-rate maximization on the interference channel. Wireless Communication Systems (ISWCS), 2012 International Symposium on, 151–155 (2012). doi:http://dx.doi.org/10.1109/ISWCS.2012.6328348.
YA Sambo, MZ Shakir, KA Qaraqe, E Serpedin, MA Imran, Expanding cellular coverage via cell-edge deployment in heterogeneous networks: spectral efficiency and backhaul power consumption perspectives. Commun. Mag. IEEE. 52(6), 140–149 (2014). doi:http://dx.doi.org/10.1109/MCOM.2014.6829956.
H Lv, T Liu, X Hou, C Yang, Adaptive interference alignment for femtocell networks. Signal Processing (ICSP), 2010 IEEE 10th International Conference on, 1654–1657 (2010). doi:http://dx.doi.org/10.1109/ICOSP.2010.5656457.
B Guler, A Yener, Interference alignment for cooperative MIMO femtocell networks. IEEE Global Commun. Conference (GLOBECOM), 2011 IEEE, 1–5 (2011).
B Guler, A Yener, Selective interference alignment for MIMO femtocell networks, 3323–3327 (2013). doi:http://dx.doi.org/10.1109/ICC.2013.6655059.
W Shin, W Noh, K Jang, H-H Choi, Hierarchical interference alignment for downlink heterogeneous networks. Wirel. Commun. IEEE Trans. 11(12), 4549–4559 (2012). doi:http://dx.doi.org/10.1109/TWC.2012.101912.120421.
T Akitaya, T Saba, in Signal and Information Processing Association Annual Summit and Conference (APSIPA), 2013 Asia-Pacific. Hierarchical multi-stage interference alignment for downlink heterogeneous networks, (2013), pp. 1–5, doi:http://dx.doi.org/10.1109/APSIPA.2013.6694381.
E Aycan, B Ozbek, D Le Ruyet, in Wireless Communications and Networking Conference (WCNC), 2014 IEEE. Hierarchical successive stream selection for heterogeneous network interference, (2014), pp. 1143–1148, doi:http://dx.doi.org/10.1109/WCNC.2014.6952290.
M Guillaud, D Gesbert, in Global Telecommunications Conference (GLOBECOM 2011), 2011 IEEE. Interference alignment in partially connected interfering multiple-access and broadcast channels, (2011), pp. 1–5, doi:http://dx.doi.org/10.1109/GLOCOM.2011.6133957.
G Liu, M Sheng, X Wang, W Jiao, Y Li, J Li, Interference alignment for partially connected downlink MIMO heterogeneous networks. Commun. IEEE Trans.63(2), 551–564 (2015). doi:http://dx.doi.org/10.1109/TCOMM.2015.2388450.
D Lopez-Perez, I Guvenc, G de la Roche, M Kountouris, TQS Quek, J Zhang, Enhanced intercell interference coordination challenges in heterogeneous networks. Wirel. Commun. IEEE. 18(3), 22–30 (2011). doi:http://dx.doi.org/10.1109/MWC.2011.5876497.
A Ghosh, N Mangalvedhe, R Ratasuk, B Mondal, M Cudak, E Visotsky, TA Thomas, JG Andrews, P Xia, HS Jo, HS Dhillon, TD Novlan, Heterogeneous cellular networks: from theory to practice. Commun. Mag. IEEE. 50(6), 54–64 (2012). doi:http://dx.doi.org/10.1109/MCOM.2012.6211486.
N Bhushan, J Li, D Malladi, R Gilmore, D Brenner, A Damnjanovic, R Sukhavasi, C Patel, S Geirhofer, Network densification: the dominant theme for wireless evolution into 5G. Commun. Mag. IEEE. 52(2), 82–89 (2014). doi:http://dx.doi.org/10.1109/MCOM.2014.6736747.
GH Golub, CF Van Loan, Matrix Computations (3rd Ed.) (Johns Hopkins University Press, Baltimore, MD, USA, 1996).
KH Rosen, Discrete Mathematics and Its Applications (McGraw-Hill, Inc., New York, 2012).
3GPP, Further advancements for E-UTRA, Technical Report 3GPP TR 36.814 v 9.0.0, TR 36.814, Further advancements for E-UTRA. 9: (2010). http://www.3gpp.org/dynareport/36814.htm.
A Leon-Garcia, Probability, Statistics, and Random Processes for Electrical Engineering (Pearson/Prentice Hall, Upper Saddle River, NJ, 2008).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License(http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Aycan Beyazıt, E., Özbek, B. & Le Ruyet, D. On stream selection for interference alignment in heterogeneous networks. J Wireless Com Network 2016, 80 (2016). https://doi.org/10.1186/s13638-016-0575-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13638-016-0575-7