- Research
- Open access
- Published:
Channel estimation for FDD massive MIMO system by exploiting the sparse structures in angular domain
EURASIP Journal on Wireless Communications and Networking volume 2019, Article number: 32 (2019)
Abstract
Massive multiple-input multiple-output (MIMO) is a powerful supporting technology to meet the energy/spectral efficiency and reliability requirement of Internet of Things (IoT) network. However, the gain of massive MIMO relies on the availability of channel state information (CSI). In this paper, we investigate the channel estimation problem for frequency division duplex (FDD) massive MIMO system. By analyzing the sparse property of the downlink massive MIMO channel in the angular domain, a structured prior-based sparse Bayesian learning (SP-SBL) approach is proposed to estimate the downlink channels between base station (BS) and users reliably. The scheme can be implemented without the knowledge of channel statistics and angular information of users. The simulation results show that the proposed scheme outperforms the reference schemes significantly in terms of normalized mean square error (NMSE) for a variety of scenarios with different lengths of pilot sequence, transmit signal-to-noise ratios (SNRs), and angular spreads.
1 Introduction
As an emerging technology that aims to allow everything to connect, interact, and exchange data, the Internet of Things (IoT) has attracted extensive attention in various areas such as governments, industry, and academia [1]. The massive connectivity, strict energy limitation, and requirement of ultra-reliable transmission are often termed as the most distinct features of IoT [2, 3]. These features make massive multiple-input multiple-output (MIMO) [4] a natural supporting technology for IoT since through coherent processing over the signals of large-scale antenna array, massive MIMO can produce tremendous spectral/energy efficiency gain and improve the reliability of IoT transmission significantly.
However, the coherent processing depends on the reliable estimation of channel state information (CSI) between base station (BS) and users [5–7]. In time division duplex (TDD) massive MIMO system, by exploiting the channel reciprocity, both the uplink and downlink channels can be obtained using the simple least square (LS) approach [8]. The consumption of pilot resource scales with the number of users. However, there is no channel reciprocity in frequency division duplex (FDD) massive MIMO system. In this case, the downlink channel estimation becomes particularly challenging since the downlink training and corresponding CSI feedback yield an unacceptably high overhead. For example, with the traditional LS channel estimation scheme, it is well-known that the length of the required pilot sequence must be larger than the number of antennas at BS [8], which will degrade the system performance greatly.
In the practical system, the BS is usually elevated at a relatively high altitude with few surrounding scatters. Therefore, the scattering process often occurs in vicinity of user, which results in very narrow signal angle of departure (AoD) at BS [8, 9] for far-field transmission. Based on a physical channel model, several works have shown that the signals from different antennas of BS exhibit high correlation, and hence, the channel between BS and user can be represented by a sparse vector in some alternate domain (usually called angular domain) [10, 11]. This property can be utilized to design cost-efficient channel estimation schemes [12–14]. The main idea behind is to transform the channel to the angular domain by exploiting the correlations between the channel elements and then estimate the effective low-dimension angular-domain channel with the LS or minimum mean square error (MMSE) method. In this way, the training consumption can be reduced greatly. However, these schemes require the knowledge of channel covariance matrix or angular-domain information, such as the AoDs of the signals, which is not always available. Another path to reduce the training overhead is to formulate the channel estimation as a sparse recovery problem and estimate the angular-domain channel using the algorithms in compressive sensing, such as orthogonal matching pursuit (OMP) [15, 16] and sparse Bayesian learning (SBL) [17]. These schemes do not need the channel covariance matrix and angular information; however, suffer from performance loss when the length of pilot sequence is small. To improve the quality of channel estimation, novel channel estimation schemes based on block l1/l2 optimization [18] and variational SBL [19] were proposed recently. These schemes exploit the structures in the channel sparsity to give a robust channel estimation.
In this paper, we investigate the downlink channel estimation problem for FDD massive MIMO system considering the above challenges. The main contributions are as follows:
-
1
The sparse property of downlink massive MIMO channel in angular domain is analyzed theoretically. The results show that the angular-domain channel exhibits two kinds of sparse structures, namely the joint sparsity and burst sparsity.
-
2
By exploiting the two kinds of sparsity, a structured prior-based SBL (SP-SBL) approach is proposed to estimate the downlink channel between the BS and user reliably. The scheme does not require the channel statistics and AoD information.
-
3
Extensive numerical simulations are presented to validate the effectiveness of the proposed scheme. The results show that the proposed scheme outperforms the reference schemes significantly in terms of normalized mean square error (NMSE) for a variety of scenarios with different lengths of pilot sequence, transmit signal-to-noise ratios (SNRs), and angular spreads.
Notations: We use B∗, BT, BH, |B|, and ∥B∥ to denote conjugate, transpose, conjugate transpose, determinant, and Frobenius norm of matrix B, respectively. \(\mathbf {B} \in \mathbb C^{N \times M}\) means B is an N×M complex-valued matrix. \({\mathcal {C}N}\left (\mathbf {b} \left | \mathbf {m},\mathbf {C}\right. \right)\) means that b is a complex Gaussian variable with mean m and covariance matrix C. [B]i,j denotes the {i,j}th element of matrix B. \(\mathbb E(\cdot)\) denotes the expectation. ∇b(f(b)) denotes the gradient of function f(b) w.r.t. the vector b.
2 Methods
The rest of the paper is organized as follows: Section 3 describes the system model of the FDD massive MIMO system. Section 4 analyzes the sparse property of the angular-domain channel and presents the SP-SBL-based channel estimation scheme. Section 5 presents the simulation results to validate the effectiveness of the proposed scheme. Section 6 draws the conclusions.
3 System model
Consider the massive MIMO system with a BS and K users. It is assumed that both the BS and users are equipped with uniform linear arrays (ULAs) with half wavelength antenna spacing. The numbers of antennas at BS and user are N and M, respectively, which satisfy M≪N. According to the ray-tracing model [8], the downlink channel between BS and user k can be expressed as:
where θk denotes AoD w.r.t. the array of BS, and φk denotes the angle of arrival (AoA) w.r.t. the array of user k. Δd and Δa denote the corresponding angular spreads. rk(θ,φ) denotes the complex channel gain for angle {θ,φ}. aBS(θ) and aU(φ) denote the array steering vectors, which are given by:
In practice, the BS is often deployed at a high place such as the top of high building. As discussed in the introduction, the limited number of scatterers around BS will result in very narrow angular spread Δd in far-field propagation. Conversely, the waves arriving at the user are usually uniformly distributed in AoA. Therefore, it is reasonable to assume Δa is close to π [9]. Note that the proposed channel estimation scheme in the next section is very general, which is valid for arbitrary Δa.
Let S denote the N×T pilot matrix of BS which is broadcasted in T successive symbol times. The power of each pilot symbol is |[S]i,j|2=P. For a practical training scheme, T should be much smaller than N. The received training signal at user k can be expressed as:
where \(\mathbf {N} \in \mathbb C^{M\times T}\) denotes the additive white Gaussian noise (AWGN) matrix whose elements have zero mean and variance σ2.
Note that for the full-duplex massive MIMO system with separate antenna configuration [11], the channel reciprocity is also not available which makes the downlink channel estimation very challenging. Since the downlink transmission model of full-duplex massive MIMO is similar with the FDD counterpart in the above, the proposed scheme can be utilized to estimate the downlink channel directly to reduce the pilot consumption.
4 Channel estimation by exploiting the sparse structures
In this section, we first analyze the property of channel sparsity in the angular domain. Based on the theoretical results, we propose a novel SP-SBL approach to estimate the downlink channel between BS and user.
4.1 Joint and burst sparsity in the angular domain
According to [11], the angular-domain channel matrix between BS and user k can be expressed as:
where AN is a shifted discrete Fourier transform (DFT) matrix of dimension N, that is:
Note that the mth column of Xk (denoted by xk,m) is the angular-domain channel vector between the BS and the mth antenna of user k. The angular-domain channel is the projection of channel onto the space spanned by the DFT bases. Since a DFT basis is in fact equivalent to an array steering vector with specific AoD, the angular-domain channel can be viewed as the channel response in the angular domain, and the amplitude of each angular-domain channel element indicates the channel strength for the path with specific AoD. Moreover, due to the limited number of scatterers around the BS, the spread of AoD will be very narrow in far-field propagation scenario. As a result, only a small fraction of elements in angular-domain channel matrix has significant amplitude. This results in the sparsity in angular-domain channel.
Mathematically, following a similar analytic approach as that in [10, 11], it can be shown that the angular-domain channel matrix has the following two kinds of sparse structures.
-
Joint sparsity among the columns of Xk: The nth element of xk,m has a significant amplitude only when n∈Ωk, where Ωk is given by \({\Omega _{k}} = \left \{ n\left | { - \frac {1}{2} + \frac {{n - 1}}{N} \in } \right.\left [ {\frac {1}{2}\sin \left ({{\theta _{k}} - {\Delta _{d}}} \right),\frac {1}{2}\sin \left ({{\theta _{k}} + {\Delta _{d}}} \right)} \right ], \right. \left.n \in {\mathbb N^ +} \right \}\). Since Ωk is independent of the column index m, the indexes of the significant elements in each column of Xk are the same.
-
Burst sparsity in each column of Xk: The indexes of significant elements in xk,m appear in block.
As discussed in the above, Δd is commonly small. Thus, only a small number of elements in xk,m has a significant value. Physically, the joint sparsity of angular-domain channel is due to the fact that the size of the user’s array can be neglected in far-field propagation, and thus, the channels between the BS and all antennas of user can be considered to have similar property in the angular domain. Moreover, it is noted that the AoD of downink signal varies in a continuous interval [θk−Δd,θk+Δd]. This causes the burst sparsity nature in the angular-domain channel. The two kinds of sparse structures are shown in Fig. 1 for an example with N=64 and M=4.

Normalized amplitudes for the elements of angular-domain channel matrix Xk, where N=64, M=4, and θk=15.5°. The angular spread for AoD is δd=5°. It is assumed that the waves arriving at the user are usually uniformly distributed in AoA [12]. Therefore, Δa is equal to π
Here, we shall point out that, for the practical system with finite N, the nth element of xk,m with n∉Ωk is small but not zero as shown in Fig. 1. Therefore, xk,m is in fact approximately sparse. Note that [16, 18] assumed that the angular-domain channel element is exactly zero if n∉Ωk, which we call as exactly sparse channel. Although this assumption simplifies the model, it may change the real system performance in the high SNR region greatly as will be shown in the simulation of Section 5.
4.2 Structured prior-based Bayesian channel estimation
By substituting (4) in (3), the received training signal at user k can be rewritten as:
where \({\Phi } = {\textbf {S}^{H}}{\textbf {A}_{N}} \in {\mathbb C^{T \times N}}\). Note that as long as Xk is known, the channel matrix Hk can be recovered directly based on (4), that is, Hk=AXk (which is called basis expansion model).
By treating Φ as the sensing matrix, Xk can be estimated using the conventional SBL [17] or OMP [15] approach from (6). However, the performance will be poor if the number of pilot symbols (i.e., T) is small as will be seen in the simulations. In this paper, we propose a SP-SBL approach to estimate the channel reliably by exploiting the two kinds of sparse structures discussed in the last subsection.
Different from the conventional SBL where a i.i.d. Gaussian prior is utilized, we propose a structured prior for Xk as follows:
where γk=[γk,1,⋯,γk,M]T and αk=[αk,1,⋯,αk,N]T. Dk an N×N diagonal matrix whose nth diagonal element is modeled as:
For the prior model in (7) and (8), the mth column of angular-domain channel matrix Xk has precision matrix γk,mDk. Thus, precision matrices for different columns of Xk differ only with a scaling factor γk,m. This property captures the joint sparsity among the columns of Xk. The parameter γk,m is utilized to model the relative difference between the amplitudes of \(\phantom {\dot {i}\!}\left \{ {{\textbf {x}_{k,m}}} \right \}_{m = 1}^{M}\). By exploiting the joint sparsity, the recovery errors which predict zero for one element of xk,m and predict non-zero for the element of \(\phantom {\dot {i}\!}{\textbf {x}_{k,m'}}\) (m≠m′) in the same position can be mitigated effectively.
Additionally, the precision of the nth element of xk,m can be expressed as γk,m(αk,n−1+αk,n+αk,n+1). Thus, the precisions of adjacent elements in xk,m are mutually coupled. When αk,n→∞, the estimations of nth, (n−1)th, and (n+1)th elements of xk,m will be driven to zero simultaneously. Therefore, the zero elements (and hence non-zero elements) in the estimation of xk,m will appear in block, which just captures the block sparsity structure. By exploiting burst sparsity, the situation that a significant element of xk,m is predicted as zero (or near zero), isolated in xk,m, can be reduced greatly. Note that the precisions of the first and the last elements of xk,m are also coupled. This structure captures a basic property of angular-domain channel, i.e., the elements at the beginning and that at the end of xk,m tend to be close to zero or have large amplitude simultaneously.
According to (6), the likelihood function of the received training signal Yk can be expressed as:
Using (7), (9), and the property of complex Gaussian distribution, the posterior distribution of xk,m can be derived as:
where the posterior mean and covariance matrix of xk,m are given by:
To give a fully Bayesian treatment, similar to conventional SBL, we introduce a gamma hyperprior for αk:
where a and b are fixed parameters. Commonly, a and b are set as small values to impose a non-informative prior. In this paper, a and b are chosen as a=b=10−4. Moreover, we introduce a Dirichlet hyperprior for γk:
where u=[u0,⋯,uM] is a fixed parameter with \(u_{0} = \sum _{m=1}^{M} u_{m}\). \(C\left (\textbf {u} \right) = \frac {{\Gamma \left ({{u_{0}}} \right)}}{{\Gamma \left ({{u_{1}}} \right) \cdots \Gamma \left ({{u_{M}}} \right)}}\) is the normalization constant. Since the expectation of γk,m with respect to the distribution (13) is given by \(\mathbb E\left [ {{\gamma _{k,m}}} \right ] = \frac {{{u_{m}}}}{{{u_{0}}}}\), we can interpret u as the parameter which gives an initial guess on the relative difference between the amplitudes of \(\left \{\mathbf {x}_{k,m}\right \}_{m=1}^{M}\).
As in the convention of sparse Bayesian learning framework, the hyperpriors are utilized to imbed the prior knowledge of the parameters into the estimation algorithm. Moreover, as shown in [17], the utilization of gamma hyperprior is helpful to produce a sparse solution which is desired in our problem.
As long as αk and γk are obtained, the maximum posterior (MAP) estimation of Xk can be given by its posterior mean in (11). Therefore, in the following, we focus on finding the optimal αk and γk by solving the MAP problem:
Different from the conventional SBL, solving the above problem directly is quite challenging due to the utilization of the structured prior. To address this problem, we resort to the expectation maximization (EM) [20] algorithm to find a computationally efficient solution.
4.3 Solving the SP-SBL using expectation maximization
Instead of solving the MAP problem in (14) directly, the EM algorithm tries to find the optimal αk and γk by maximizing the expected complete-data log-likelihood function, that is:
where the expectation is w.r.t. the posterior distribution of Xk given by (10). \({\hat {\alpha }}_{k}^{{\text {old}}}\) and \({\hat {\gamma }}_{k}^{{\text {old}}}\) denote the latest estimations of αk and γk, respectively. Each iteration of the algorithm consists of an expectation step (E-step) and a maximization step (M-step).
In the E-step of the ith iteration, the posterior distribution of Xk is computed approximately using the estimations of αk and γk in the (i−1)th iteration \(\left (\text {denoted by}\ {\hat {\alpha }}_{k}^{(i-1)}\ \text {and}\ {\hat {\gamma }}_{k}^{(i-1)}\right)\) based on (10), which is then used to evaluate the expected complete-data log-likelihood function.
In the M-step of the ith iteration, the estimation of αk and γk is updated to maximize the expected complete-data log-likelihood function obtained in E-step.
4.3.1 Update of γ k
By substituting (10) and (13) into (15) and discarding the terms irrelevant to γk, it can be shown that the expected complete-data log-likelihood function reduces to"
Note that αk has been fixed at its estimation after the last iteration, i.e., \({ \alpha }_{k} = \hat {\alpha }_{k}^{(i-1)}\). \({{\hat {\mathbf {D}}_{k}}}\) can be computed using (8) by replacing αk with \( \hat {\alpha }_{k}^{(i-1)}\). \({{{\hat {\Sigma } }_{k,m}}}\) and \( {{\hat {{\mu }}}_{k,m}}\) can be computed using (11) by replacing {αk,γk} with \(\left \{{{{\hat {\alpha } }_{k}^{(i-1)}}}, {{{\hat {\gamma } }_{k}^{(i-1)}}}\right \}\). The first-order derivative of \(Q\left ({{{\hat {\alpha }}_{k}^{(i-1)}},{{\gamma }_{k}}} \right)\) w.r.t γk,m can be expressed as:
By setting (17) to zero, we can obtain the estimation for γk,m in the ith iteration:
4.3.2 Update of α k
By substituting (10) and (12) into (15) and discarding the terms irrelevant to αk, it can be shown that the expected complete-data log-likelihood function reduces to:
where γk has been fixed at its estimation after the last iteration, i.e., \({ \gamma }_{k} ={\hat {\gamma }}_{k}^{(i-1)}\). The first-order derivative of \(Q\left ({{{{\alpha }}_{k}},{{\hat {\gamma } }_{k}^{(i-1)}}} \right)\) w.r.t αk,n can be expressed as:
with
In (21), the derivative w.r.t. αk,n is correlated with αk,n−2, αk,n−1, αk,n+1, and αk,n+2. This makes the closed-form solution for αk,n unavailable. Nevertheless, we can obtain a valid solution using the gradient-based algorithm as follows:
where δ is the stepsize, and the gradient can be directly computed using (20).
By virtue of the EM’s properties, the above algorithm will always converge since each iteration is guaranteed to reduce the target function. However, the update formula of αk in (22) is still complex due to the lack of analytic expressions. Moreover, (22) gives little insight into the basic mechanism of SP-SBL. In the following, we derive a closed-form solution for αk by adding some heuristic assumptions.
When updating αk,n, we temporarily assume that the nth element of xk,m has the same variance with its neighbors, i.e., the (n−1)th and (n+1)th elements of xk,m. In this case, we will have αk,n−2=αk,n−1=αk,n=αk,n+1=αk,n+2. This assumption is reasonable if we do not have much prior knowledge about αk. Note that this does not mean we will obtain an estimation of αk with \(\hat {\alpha }_{k,n-2}^{(i)}=\hat {\alpha }_{k,n-1}^{(i)}=\hat {\alpha }_{k,n}^{(i)}=\hat {\alpha }_{k,n+1}^{(i)}=\hat {\alpha }_{k,n +2}^{(i)}\) because, with the incoming training signal, the estimation of αk,n is rectified and is expected to get close to the true value. Under this assumption, (20) becomes:
By setting (23) to zero, we can obtain:
The numerical results show that the update formula in (24) gives rise to the similar performance with that using gradient-based update in (22). Moreover, the solution in (24) provides a clear insight into the difference between SP-SBL and conventional SBL. With conventional SBL, the update of the precision for the nth element of xk,m is only related to the posterior mean and variance of itself. In contrast, in SP-SBL, the update of αk,n is effected by the posterior means and variances of (n−1)th, nth, and (n+1)th elements of xk,m for all m=1,⋯,M due to the utilization of joint and burst sparsity. Therefore, the SP-SBL is expected to achieve better performance.
After the downlink channel estimation, the estimated CSI should be sent back to the BS in order to perform the downlink beamforming. In this process, additional error can be introduced by quantization, noise, and feedback delay. However, the results in [21] showed that the error due to the imperfect feedback can be made much smaller than that due to the estimation error in downlink training phase. Therefore, as in [11], we optimistically neglect the additional error due to the feedback in this paper.
4.4 Computation complexity analysis
The main computation load in each iteration is due to the N×N matrix inversion when updating the posterior mean and covariance matrix of xk,m in E-step. By using the matrix inversion lemma, the calculation of each matrix inversion has complexity \({\mathcal {O}}\left (T^{3}\right)\). Therefore, the overall computational complexity of the algorithm scales with \({\mathcal {O}}\left (GKMT^{3}\right)\), where G is the number of EM iterations. Since we consider the situation that T is much smaller than N, the computation complexity will not pose a significant problem.
4.5 Extension to FDD massive MIMO system with hybrid analog-digital processing
In the practical system, the hybrid analog-digital processing may be utilized at the BS to reduce the implementation complexity. In the following, we will show that the proposed scheme can still be applied in this case. With hybrid analog-digital processing at the BS, the received training signal at user k can be expressed as:
where \(\mathbf {W}\in \mathbb C^{N \times F}\) is the arbitrary analog beamforming matrix utilized by BS, and F≤N denotes the number of radio frequency chain at the BS. The pilot signal S is an F×T matrix in this case. Note that we have reuse some notations to avoid introducing too many new definitions. Using the definition of angular-domain channel in (4), we can rewrite (25) as:
Note that, by treating (WS)HAN as the sensing matrix, (26) is in the same form with (6). Therefore, the proposed scheme can be utilized directly to estimation the channel matrix from (26).
5 Simulation results and discussion
This section presents the simulation results to validate the proposed scheme. Without loss of the generality, the large-scale fading and noise variance are normalized to 1. For illustration, the number of users is set to K=8. The central frequency is set to 2.4 GHz, and the antenna spacing is equal to the half of wavelength. Similar to [22], the rows of sensing matrix Φ are designed as the length-N Zadoff-Chu sequence [23] with shifting step 7. In particular, the first row of Φ is given by \(\frac {1}{{\sqrt N }}\left [ {1,{e^{j\frac {{\nu \pi {1^{2}}}}{N}}},{e^{j\frac {{\nu \pi {2^{2}}}}{N}}}, \cdots,{e^{j\frac {{\nu \pi {{\left ({N - 1} \right)}^{2}}}}{N}}}} \right ]\). The second row of Φ is obtained by cyclically right shifting the first row with a step of 7, which is given by \(\frac {1}{{\sqrt N }}\left [ {{e^{j\frac {{\nu \pi {{\left ({N - 7} \right)}^{2}}}}{N}}},{e^{j\frac {{\nu \pi {{\left ({N - 6} \right)}^{2}}}}{N}}}, \cdots,{e^{j\frac {{\nu \pi {{\left ({N - 1} \right)}^{2}}}}{N}}},1,{e^{j\frac {{\nu \pi {1^{2}}}}{N}}},{e^{j\frac {{\nu \pi {2^{2}}}}{N}}},} \right. \left. { \cdots,{e^{j\frac {{\nu \pi {{\left ({N - 8} \right)}^{2}}}}{N}}}} \right ]\). Moreover, ν=7 is used in the simulations. The rest rows of Φ are generated in a similar way. The AoD θk and AoA φk for different users are generated randomly from the interval [−90°,90°]. It is assumed that the waves arriving at the user are uniformly distributed in AoA [12]. Therefore, Δa is equal to π, and the complex channel gain reduces to rk(θ,φ)=rk(θ). It is assumed that the rk(θ) for different θ are uncorrelated. For each sample of θ, rk(θ) is the complex Gaussian distributed with zero mean and variance Uk(θ), where Uk(θ) is the power angle spectrum. We model Uk(θ) as the truncated Laplacian distribution centered at θk [12]. The simplified update rule for αk in (24) is utilized to reduce the complexity. The parameters in the hyperprior models (12) and (13) are set as a=b=10−4, u1=⋯=uM, and u0=M.
We consider four reference schemes in the simulations, i.e., the conventional SBL based on the original algorithm in [17], OMP [15], block l1/l2 minimization [18], and variational SBL [19]. Note that the block l1/l2 minimization and variational SBL can also exploit the joint sparsity among the angular-domain channel vectors between BS and different antennas of user.
We consider the NMSE performance which is defined as follows:
All figures are obtained by averaging the results for 103 independent channel realizations.
Figure 2 shows the NMSE performance for different lengths of pilot sequence T, where the transmit SNR of BS is \(\frac {NP}{\sigma ^{2}} = 15\) dB and the angular spread is Δd=5°. It is seen that the performances of conventional SBL and OMP are poor when the length of pilot sequence is small. By exploiting the joint sparsity among the angular-domain channel vectors between BS and different antennas of user, the block l1/l2 minimization and variational SBL can provide better performance. Moreover, the proposed scheme based on SP-SBL achieves the best NMSE performance since it exploits the joint sparsity and burst sparsity simultaneously.

NMSE performance for different lengths of pilot sequence T, where N=64 and M=4. The transmit SNR of BS is \(\frac {NP}{\sigma ^{2}} = 15\) dB and the angular spread is Δd=5°
Figure 3 shows the NMSE performance for different transmit SNRs of BS, where the length of pilot sequence is T=16 and the angular spread is Δd=5°. It is seen that the performances of all schemes converge to NMSE floors for large SNR. The reason is that the angular-domain channel is approximately sparse as discussed in Section 4.1. That is, the nth element of xk,m with n∉Ωk is small but not zero. With small T, recovering all these small elements of xk,m with high accuracy is difficult. As a result, with the increasing of the SNR, the effect of the mismatch between the true values of these small elements and their estimates becomes significant when compared with AWGN, which incurs NMSE floor in the high SNR regionFootnote 1. Note that the NMSE floor does not occur in the simulations of [16, 18]. This is because these works assume that there is no channel power leakage outside Ωk. Although this assumption simplifies the model, the resultant simulations cannot reflect the real performance in the high SNR region very well. For illustration, we also present the NMSE performance for all schemes in Fig. 4 under exactly sparse angular-domain channel model considered in [16, 18], where the nth element of xk,m is set to zero as long as n∉Ωk when generating the channel matrix. From the figure, we can see that the performance floors disappear as expected.

NMSE performance for different transmit SNRs of BS, where N=64 and M=4. The length of pilot sequence is T=16 and the angular spread is Δd=5°. The angular-domain channel is assumed exactly sparse
Then, we consider the performance for different angular spreads Δd ranged from 3 to 18°. This corresponds to the scenarios with scattering ring of 30 m and the distance between BS and user varying from about 100 to 500 m. Figure 5 shows the number of significant elements in the angular-domain channel xk,m, i.e., the number of elements that contain 90% of the channel power, varies from 3 to 17 when the angular spread increases from 3 to 18°. Figure 6 shows the NMSE performance for different angular spreads, where the transmit SNR of BS is \(\frac {NP}{\sigma ^{2}} = 15\) dB and the length of pilot sequence is T=16. Again, the proposed scheme based on SP-SBL achieves the best performance. Moreover, we note that the NMSEs of all schemes degrade when the angular spread increases. This is because the number of significant elements in angular-domain channel becomes larger as shown in Fig. 5. In this case, to maintain the estimation performance, the capacity of all schemes must be enhanced by increasing the training samples.

Number of significant elements in xk,m, where N=64 and M=4

NMSE performance for different angular spreads Δd, where N=64 and M=4. The length of pilot sequence is T=16 and the transmit SNR of BS is \(\frac {NP}{\sigma ^{2}} = 15\) dB
Figure 7 shows the NMSE performance for different numbers of antennas at user, i.e., M. The length of pilot sequence is T=16. The transmit SNR of BS is \(\frac {NP}{\sigma ^{2}} = 15\) dB. The angular spread is Δd=5°. It is seen that the NMSEs of conventional SBL and OMP-based schemes are independent of M. In contrast, the performances of block l1/l2 minimization, variational SBL, and SP-SBL-based schemes are improved gradually with the increasing of M, which is just the benefit of exploiting the joint sparsity.

NMSE performance for different numbers of antennas at users, i.e., M, where N=64. The length of pilot sequence is T=16. Transmit SNR of BS is \(\frac {NP}{\sigma ^{2}} = 15\) dB. The angular spread is Δd=5°
Figure 8 shows the NMSE performance for different numbers of iterations. The length of pilot sequence is T=16. The transmit SNR of BS is \(\frac {NP}{\sigma ^{2}} = 15\) dB. The angular spread is Δd=5°. It is seen that the NMSE performance converges after 40 EM iterations. Moreover, the number of iterations required for SP-SBL is smaller than that of block l1/l2 minimization and greater than that of conventional SBL and variational SBL. The computation complexities in each iteration for SP-SBL, block l1/l2 minimization, conventional SBL, and variational SBL are \({\mathcal {O}}\left (KMT^{3}\right)\), \({\mathcal {O}}\left (KMNT\right)\) [18], \({\mathcal {O}}\left (KMT^{3}\right)\) [17], and \({\mathcal {O}}\left (KMT^{3}\right)\) [19], respectively. Note that the OMP needs no iteration and its total computation complexity is \({\mathcal {O}}\left (\eta KMNT\right)\) [15], where η denotes the number of significant elements in xk,m. Therefore, from the analysis above, the SP-SBL has the highest computation complexity but converges to best NMSE.

NMSE performance for different numbers of iterations, where N=64. The length of pilot sequence is T=16. Transmit SNR of BS is \(\frac {NP}{\sigma ^{2}} = 15\) dB. The angular spread is Δd=5°
6 Conclusions
This paper proposes a SP-SBL approach for downlink channel estimation in FDD massive MIMO system. By exploiting the two kinds of sparse structures, the scheme can substantially reduce the pilot resource assumption while maintaining the estimation performance. Through numerical simulations, it is shown that the proposed scheme outperforms the reference schemes significantly in terms of NMSE for a variety of scenarios with different lengths of pilot sequence, transmit SNRs, and angular spreads.
Notes
To address this problem, a possible solution is to exploit other inherent structures of angular-domain channel in the prior model, for example, the additional correlation between the phases and amplitudes of the elements in angular-domain matrix if they exist. In general, the problem is quite challenging and will be considered as future study.
Fig. 3 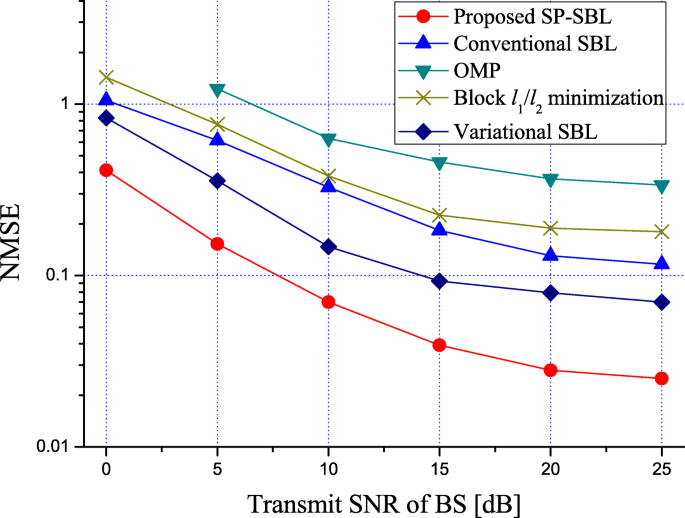
NMSE performance for different transmit SNRs of BS, where N=64 and M=4. The length of pilot sequence is T=16 and the angular spread is Δd=5°

Abbreviations
- AoA:
-
Angle of arrival
- AoD:
-
Angle of departure
- AWGN:
-
Additive white Gaussian noise
- BS:
-
Base station
- CSI:
-
Channel state information
- DFT:
-
Discrete Fourier transform
- EM:
-
Expectation maximization
- FDD:
-
Frequency division duplex
- IoT:
-
Internet of Things
- LS:
-
Least square
- MIMO:
-
Multiple-input multiple-output
- MMSE:
-
Minimum mean square error
- NMSE:
-
Normalized mean square error
- OMP:
-
Orthogonal matching pursuit
- SBL:
-
Sparse Bayesian learning
- SNR:
-
Signal-to-noise ratio
- SP-SBL:
-
Structured prior-based sparse Bayesian learning
- ULA:
-
Uniform linear array
References
J. A. Stankovic, Research directions for the Internet of Things. IEEE Internet Things J.1(1), 3–9 (2014).
T. Lv, Z. Lin, P. Huang, J. Zeng, Optimization of the energy-efficient relay-based massive IoT network. IEEE Internet Things J.5(4), 3043–3058 (2018).
C. Li, S. Zhang, P. Liu, F. Sun, J. M. Cioffi, L. Yang, Overhearing protocol design exploiting intercell interference in cooperative green networks. IEEE Trans. Veh. Technol.65(1), 441–446 (2016).
T. L. Marzetta, Noncooperative cellular wireless with unlimited numbers of base station antennas. IEEE Trans. Wirel. Commun. 9(11), 3590–3600 (2010).
C. Li, L. Yang, W. Zhu, Two-way, MIMO relay precoder design with channel state information. IEEE Trans. Commun. 58(12), 3358–3363 (2010).
C. Li, H. J. Yang, F. Sun, J. M. Cioffi, L. Yang, Multiuser overhearing for cooperative two-way multiantenna relays. IEEE Trans. Veh. Technol.65(5), 3796–3802 (2016).
C. Li, P. Liu, C. Zou, F. Sun, J. M. Cioffi, L. Yang, Spectral-efficient cellular communications with coexistent one- and two-hop transmissions. IEEE Trans. Veh. Technol. 65(8), 6765–6772 (2016).
A. Adhikary, J. Nam, J. -Y. Ahn, G. Caire, Joint spatial division and multiplexing: the large-scale array regime. IEEE Trans. Info. Theory. 59(10), 6441–6463 (2013).
C. Sun, X. Gao, S. Jin, M. Matthaiou, Z. Ding, C. Xiao, Beam division multiple access transmission for massive MIMO communications. IEEE Trans. Commun. 63(6), 2170–2184 (2015).
H. Xie, F. Gao, S. Zhang, S. Jin, A unified transmission strategy for TDD/FDD massive MIMO systems with spatial basis expansion model. IEEE Trans. Veh. Technol. 66(4), 3170–3184 (2017).
X Xia, K Xu, D Zhang, Y Xu, Y Wang, Beam-domain full-duplex massive MIMO: realizing co-time co-frequency uplink and downlink transmission in the cellular system. IEEE Trans. Veh. Technol. 66(10), 8845–8862 (2017).
L. You, X. Gao, X. Xia, N. Ma, Y. Peng, Pilot reuse for massive MIMO transmission over spatially correlated rayleigh fading channels. IEEE Trans. Wireless Commun. 14(6), 3352–3366 (2015).
L. You, X. Gao, A. L. Swindlehurst, W. Zhong, Channel acquisition for massive MIMO-OFDM with adjustable phase shift pilots. IEEE Trans. Signal Process. 64(6), 1461–1476 (2016).
L. Zhao, D. W. K. Ng, J. Yuan, Multi-user precoding and channel estimation for hybrid millimeter wave systems. IEEE J. Sel. Areas Commun. 35(7), 1576–1590 (2017).
J. Lee, G. T. Gil, Y. H. Lee, Channel estimation via orthogonal matching pursuit for hybrid MIMO systems in millimeter wave communications. IEEE Trans. Commun. 64(6), 2370–2386 (2016).
X. Rao, V. K. N. Lau, Distributed compressive CSIT estimation and feedback for FDD multi-user massive MIMO systems. IEEE Trans. Signal Process. 62(12), 3261–3271 (2014).
S. Ji, Y. Xue, L. Carin, Bayesian compressive sensing. IEEE Trans. Signal Process. 56(6), 2346–2356 (2008).
C. C. Tseng, J. Y. Wu, T. S. Lee, Enhanced compressive downlink CSI recovery for FDD massive MIMO systems using weighted block ℓ 1-minimization. IEEE Trans. Commun. 64(3), 1055–1067 (2016).
X. Cheng, J. Sun, S. Li, Channel estimation for FDD multi-user massive MIMO: a variational Bayesian inference-based approach. IEEE Trans. Wirel. Commun. 16(11), 7590–7602 (2017).
A. Dempster, Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B. 39(1), 1–38 (1977).
G. Caire, N. Jindal, M. Kobayashi, N. Ravindran, Multiuser MIMO achievable rates with downlink training and channel state feedback. IEEE Trans. Inf. Theory. 56(6), 2845–2866 (2010).
Y. Ding, S. E. Chiu, B. Rao, Bayesian channel estimation algorithms for massive MIMO systems with hybrid analog-digital processing and low-resolution ADCs. IEEE J. Sel. Top. Sig. Process. 12(3), 499–513 (2018).
D. Chu, Polyphase codes with good periodic correlation properties. IEEE Trans. Inf. Theory. 18(4), 531–532 (1972).
Funding
This work is supported by National Natural Science Foundation of China (No. 61671472) and Jiangsu Province Natural Science Foundation (BK20160079).
Availability of data and materials
Not applicable.
Author information
Authors and Affiliations
Contributions
XX provided the main idea and is responsible for the manuscript writing. YW conducted the simulations. KX, WX, and MW assisted with the revision of the manuscript. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Wang, Y., Xia, X., Xu, K. et al. Channel estimation for FDD massive MIMO system by exploiting the sparse structures in angular domain. J Wireless Com Network 2019, 32 (2019). https://doi.org/10.1186/s13638-019-1353-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13638-019-1353-0